Redis实战篇(二):秒杀问题及其优化和分布式锁与Redisson
优惠券秒杀
今天继续来学习Redis实战中的优惠券秒杀场景下碰到的问题和解决的方案
全局唯一ID
优惠券在购买后会一个购买优惠券的订单ID,这个ID是要返还给用户的。这个ID也会被用于用户退款,或者商家自己查询到底被谁买了,那么问题就来了:
- 如果使用MySQL数据库的自增id,那么总是从1开始,这样的数字过于简短,有太明显的规律,易于被用户和商业对手猜测出购买的数量等等
- 如果数量规模过大,要分库分表的话,不同的表又是从1开始,这样就会出现都是优惠券订单表,但是id相同的情况,这是很不应该的
所以我们就应该构造一个全局ID生成器,我们便可以利用Redis的可increment特性,再拼接一些信息(不同公司规则不同),去产生一个全局唯一ID
实现方法:

成部分:符号位:1bit,永远为0
时间戳:31bit,以秒为单位,可以使用69年
序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID
使用Redis实现全局唯一ID
1 |
|
在上面的代码中,使用long型的时间戳(当前时间戳与指定时间戳的差值),左移32位,再或运算上Redis中increment后生成的序列号,则可生成全局唯一ID
代码实现优惠券秒杀
这里的业务逻辑较为简单,就不多赘述,只需注意判断是否有库存即可
代码如下
1 |
|
库存超卖问题
超卖问题分析
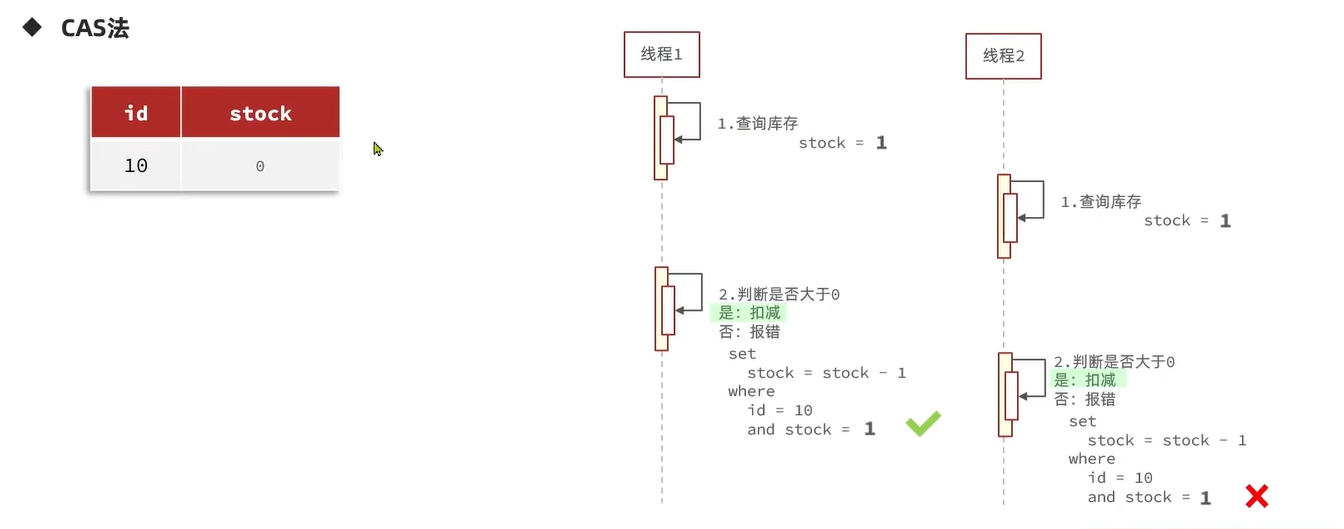
我们现在来分析一下原有逻辑的问题,在下面的代码中,我们使用了<1作为库存量的判断。
假设库存还剩1件,现在有两个线程:第一个线程查到了库存还剩1,但是还未删减库存时,另一线程也查到了库存为1,这下第一个线程先-1,由于后一个线程也查到了库存可用,也会-1,就会出现库存的超卖问题。
1 | // 5.无库存,返回异常结果 |
同样,我们使用JMeter来模拟200个人同时购买这个优惠券的情况,如图所示,会出现部分成功部分失败的情况,因为库存只有100个,只有成功的才会返回了订单ID
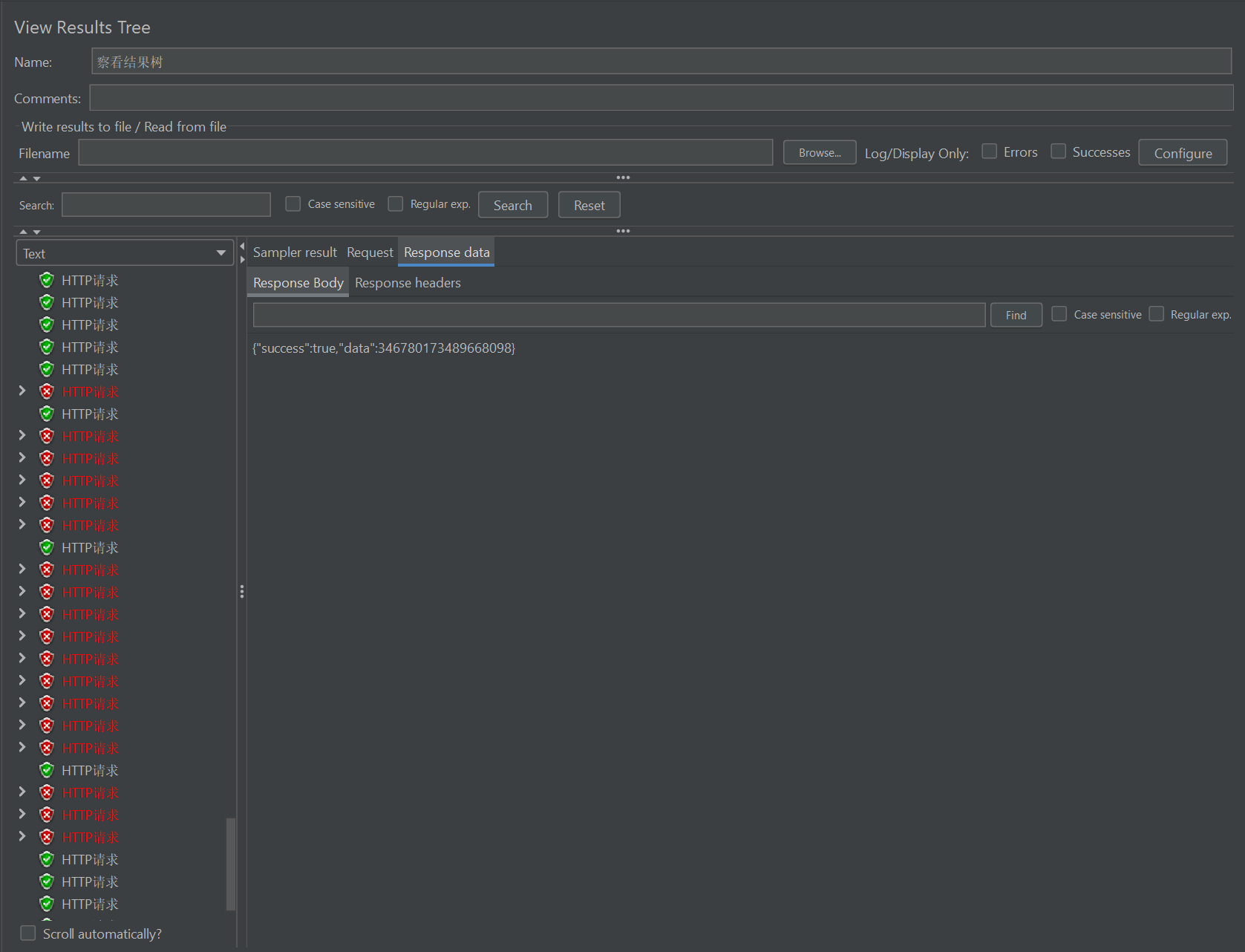
但是,并没有达到我们的预期,错误率只为45.5%而不是50%,证明还是有部分不应该成功的请求成功了

我们回到数据库中查看,此时的库存变成了-9,有109个人买到了库存仅为100的优惠券,这是绝对不允许发生的

超卖问题解决办法
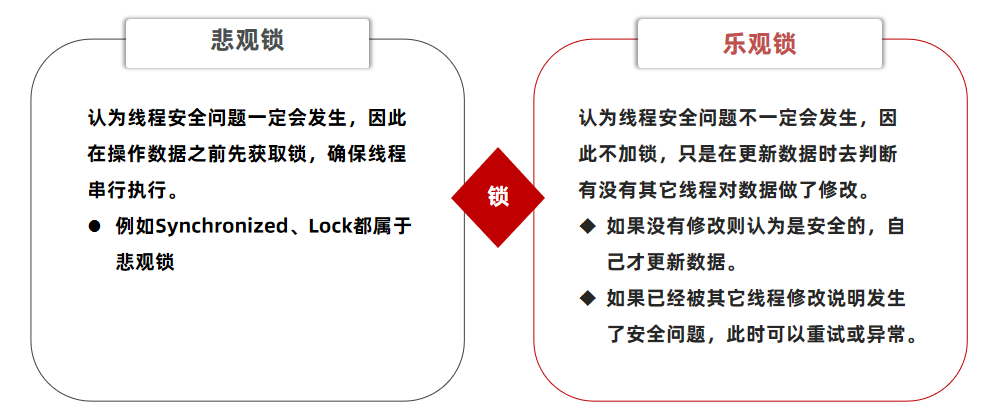
超卖问题是典型的多线程安全问题,针对这一问题的常见解决方案就是加锁:而对于加锁,我们通常有两种解决方案:见下图:
悲观锁:
悲观锁可以实现对于数据的串行化执行,比如syn,和lock都是悲观锁的代表,同时,悲观锁中又可以再细分为公平锁,非公平锁,可重入锁,等等
乐观锁:
乐观锁:会有一个版本号,每次操作数据会对版本号+1,再提交回数据时,会去校验是否比之前的版本大1 ,如果大1 ,则进行操作成功,这套机制的核心逻辑在于,如果在操作过程中,版本号只比原来大1 ,那么就意味着操作过程中没有人对他进行过修改,他的操作就是安全的,如果不大1,则数据被修改过,当然乐观锁还有一些变种的处理方式比如cas
之前用到的避免缓存击穿的互斥锁就是一个典型的悲观锁,所以我们尝试用乐观锁来解决炒卖问题
乐观锁解决超卖问题
乐观锁的关键是判断之前查询到的数据有没有被修改过,常见的方法有两种
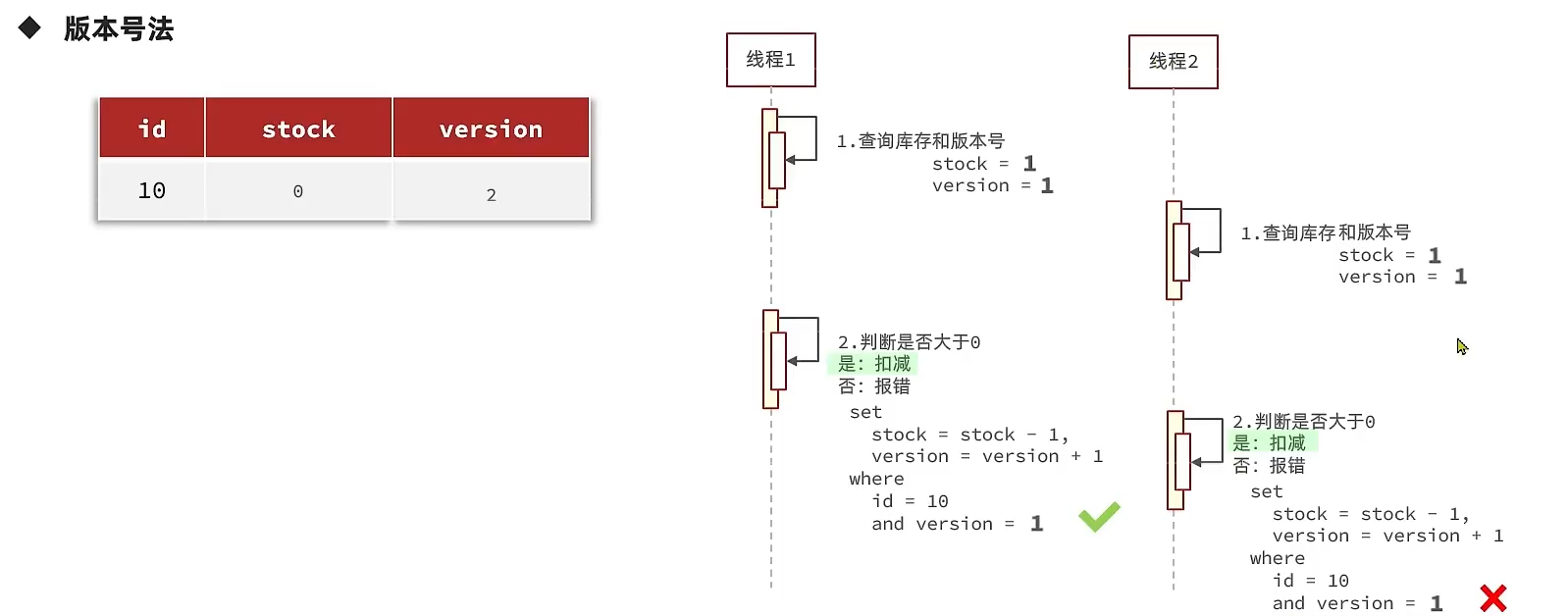
在本案例中,由于是库存,我们可以直接把stock(库存)当作是版本号,就不用新加版本号了
1 | boolean success = seckillVoucherService.update() |
再次执行测试,发现错误率高达92.50%,仅有200人中只有15人成功了!!

这是乐观锁的一个弊端,在并发线程中,同时访问到相同库存的,只有第一个可以改,其他的都发现库存被改过了,然后就不能去更改,相当于直接取消了,所以失败率大大升高
1 | //eq("stock",stock) |
此时刚好库存用完,成功率100/200=0.5,达到预期,一张不超一张不少,且前100个请求成功,符合逻辑

当然还有其他乐观锁的解决方案,但是这里的库存比较简单,就没有用上。此方案还是查询到了数据库,对于高高高并发的场景可能还会出现问题,继续学习吧,方法总比困难多。
一人一单
前面我们并没有对用户进行限制,而且为了方便,也是拿了一个token(用户)进行的测试。
实际情况中,秒杀情况正常下不允许一人买多单,出现囤货情况,避免黄牛等等
- 最简单的方法,我们判断这个userId和voucherId是否在order表中出现
1 | // 5.一人一单逻辑 |
代码完成后执行,还是存在问题:并发查询数据库都显示不存在购买记录的情况,所以我们应该给他加上一个锁
乐观锁比较适合更新数据,而现在是插入数据,所以我们需要使用悲观锁操作
注意:在这里提到了非常多的问题,我们需要慢慢的来思考,首先我们的初始方案是封装了一个createVoucherOrder方法,同时为了确保他线程安全,在方法上添加了一把synchronized 锁
1 |
|
但是这样添加锁,锁的粒度太粗了,在使用锁过程中,控制锁粒度 是一个非常重要的事情,因为如果锁的粒度太大,会导致每个线程进来都会锁住,所以我们需要去控制锁的粒度。
以下这段代码需要修改为:
intern() 这个方法是从常量池中拿到数据,如果我们直接使用userId.toString() 他拿到的对象实际上是不同的对象,new出来的对象,我们使用锁必须保证锁必须是同一把,所以我们**需要使用intern()**方法
1 |
|
但是以上代码还是存在问题,问题的原因在于当前方法被spring的事务控制。如果在方法内部加锁,可能会导致当前方法事务还没有提交,但是锁已经释放也会导致问题。所以我们选择将当前方法整体包裹起来,确保事务不会出现问题:如下:
在seckillVoucher 方法中,添加以下逻辑,这样就能保证事务的特性,同时也控制了锁的粒度
1 | Long userId = UserHolder.getUser().getId(); |
但是以上做法依然有问题,因为你调用的方法,其实是this.的方式调用的,事务想要生效,还得利用代理来生效,所以这个地方,我们需要获得原始的事务对象, 来操作事务
- 引入依赖
1 | <dependency> |
给启动类加上@EnableAspectJAutoProxy
1 |
在IVoucherOrderService接口中声明方法
1 | Result createVoucherOrder(Long voucherId); |
最后修改业务代码
1 | Long userId = UserHolder.getUser().getId(); |
运行测试,同ID只有一个请求成功,功能实现
集群环境下的并发问题
通过加syn锁可以解决在单机情况下的一人一单,但是到集群就不行了
- 在IDEA中开启两个服务
- 在nginx中开启负载均衡,请求到后端两台服务器上
1 | proxy_pass http://backend; |
然后我们使用Apifox请求两次8080前端端口,请求会分别发送到8081服务器和8082服务器,会出现一人两单的情况
原因分析:
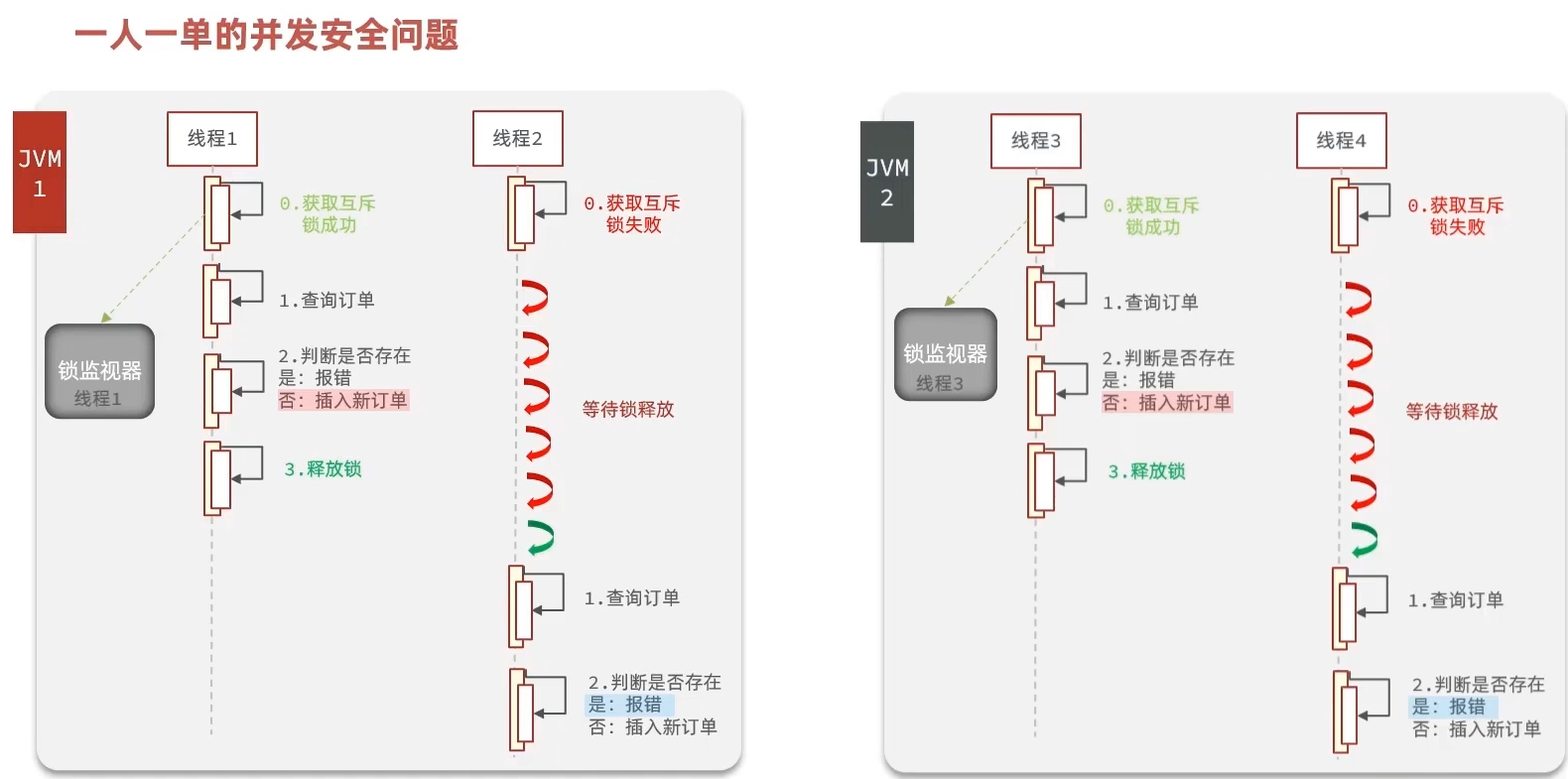
由于现在我们部署了多个tomcat,每个tomcat都有一个属于自己的JVM,JVM中有自己的锁监视器。
那么假设在服务器A的tomcat内部,有两个线程,这两个线程由于使用的是同一份代码,那么他们的锁对象是同一个,是可以实现互斥的。
但是如果现在是服务器B的tomcat内部,又有两个线程,但是他们的锁对象写的虽然和服务器A一样,但是锁对象却不是同一个,所以线程3和线程4可以实现互斥,但是却无法和线程1和线程2实现互斥,这就是集群环境下,syn锁失效的原因。
在这种情况下,我们就需要使用分布式锁来解决这个问题,实现不同JVM使用同一个锁
分布式锁
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
分布式锁的基本原理
synchronized只能保证当前JVM中的线程互斥,而没有办法让集群下的多个JVM中线程互斥
分布式锁的核心思想就是让大家都使用同一把锁,只要大家使用的是同一把锁,那么我们就能锁住线程,不让线程进行,让程序串行执行,这就是分布式锁的核心思路
分布式锁的实现方式
常见的分布式锁有三种
Mysql:mysql本身就带有锁机制,但是由于mysql性能本身一般,所以采用分布式锁的情况下,其实使用mysql作为分布式锁比较少见
Redis:redis作为分布式锁是非常常见的一种使用方式,现在企业级开发中基本都使用redis或者zookeeper作为分布式锁,利用setnx这个方法,如果插入key成功,则表示获得到了锁,如果有人插入成功,其他人插入失败则表示无法获得到锁,利用这套逻辑来实现分布式锁
Zookeeper:zookeeper也是企业级开发中较好的一个实现分布式锁的方案,由于本套视频并不讲解zookeeper的原理和分布式锁的实现,所以不过多阐述
Redis分布式锁的核心思路
实现分布式锁时需要实现的两个基本方法:
获取锁:
- 互斥:确保只能有一个线程获取锁
- 非阻塞:尝试一次,成功返回true,失败返回false(阻塞式会浪费CPU资源)
释放锁:
- 手动释放
- 超时释放:获取锁时添加一个超时时间(兜底,避免宕机没有完成手动释放)
还是基于Redis的SetNX命令来获取锁,DEL命令来释放锁
实现初级Redis分布式锁
定义ILock接口,定义两个抽象方法:tryLock()方法和unlock()方法
1 | /** |
定义ILock接口的实现类SimpleRedisLock,其中key为lock:order:userId,value为当前线程ID
利用setnx方法进行加锁,同时增加过期时间,防止死锁,此方法可以保证加锁和增加过期时间具有原子性
1 | /** |
修改业务代码,取消synchronized锁,取而代之的是我们自己创建的Redis分布式锁对象
1 | // 创建锁对象 |
至此,我们就完成了初级的Redis分布式锁实现
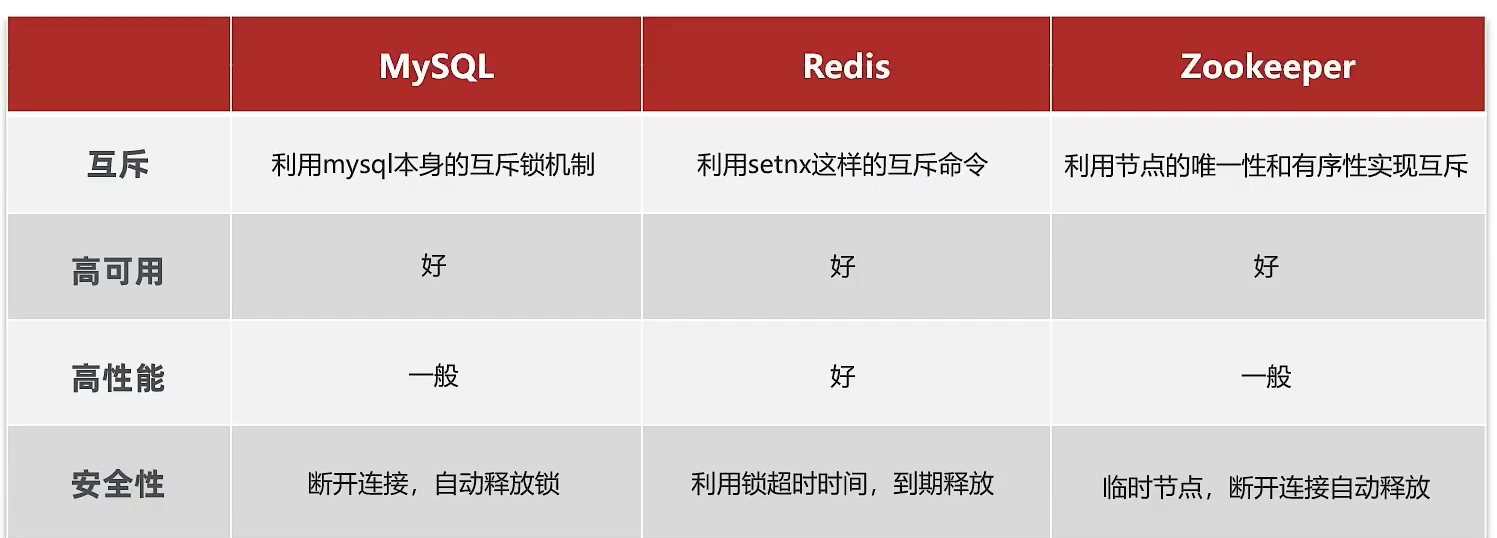
Redis分布式锁误删情况说明
逻辑说明:
持有锁的线程在锁的内部出现了阻塞,导致他的锁自动释放。这时其他线程,线程2来尝试获得锁,就拿到了这把锁。然后线程2在持有锁执行过程中,线程1反应过来,继续执行,而线程1执行过程中,走到了删除锁逻辑,此时就会把本应该属于线程2的锁进行删除,这就是误删别人锁的情况
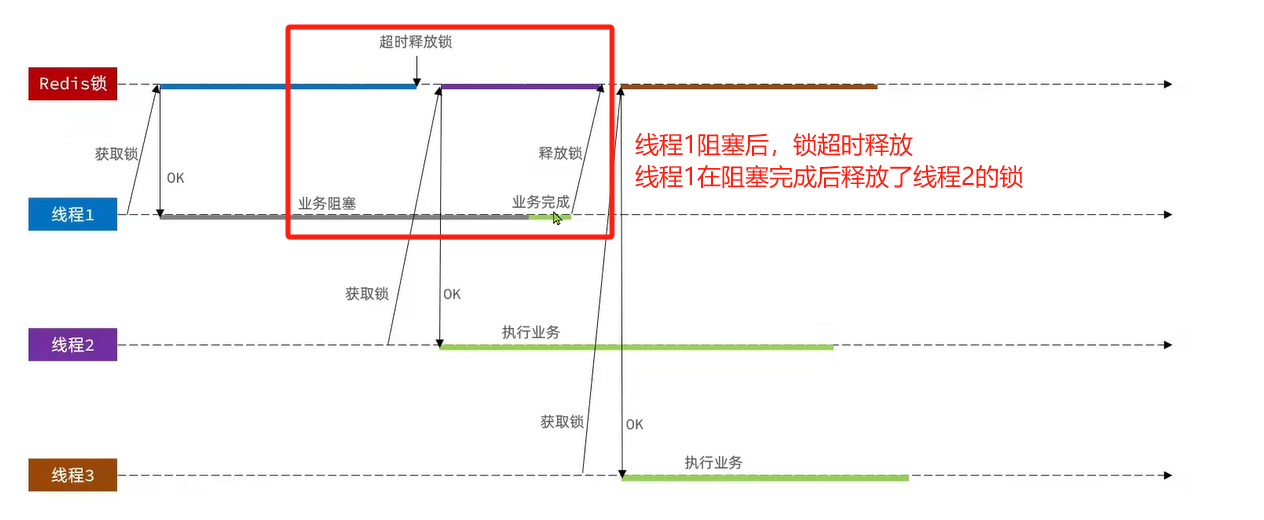
解决方案:每个线程释放锁的时候,去判断一下当前这把锁是否属于自己。如果不属于自己,则不进行锁的删除。
- 存入线程标识
解决Redis分布式锁误删问题
改造tryLock()方法和unlock()方法
- 获取锁前存入线程标识(原先使用ThreadId,但是问题是不同JVM中线程都是自增的,所以会有重复,可以使用UUID结合一下)
- 释放锁时现判断锁是不是自己的
使用UUID生成一个不带“-”(传入true参数)的随机值
1 | public static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-"; |
修改tryLock()方法
1 | public boolean tryLock(long timeoutSec) { |
修改unlock()方法
1 | public void unlock() { |
至此,误删问题就可以得到解决
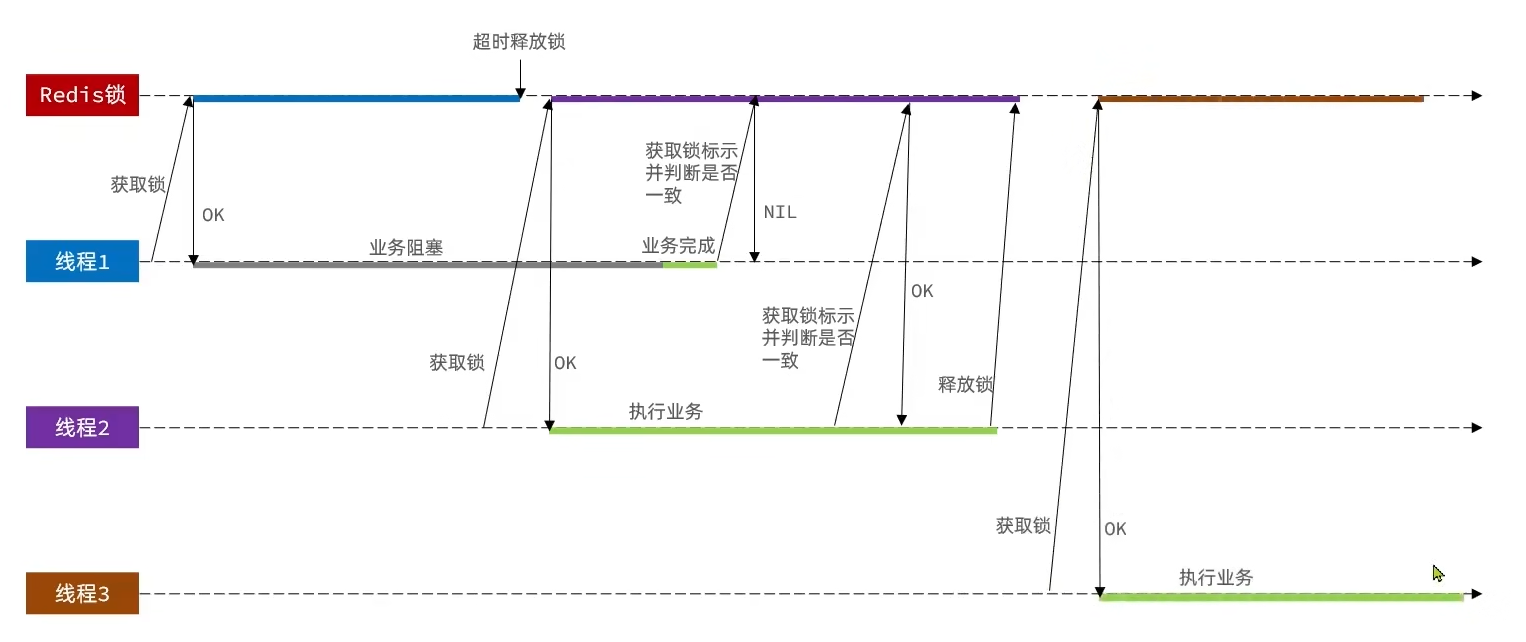
分布式锁的原子性问题
更为极端的误删逻辑说明:
线程1现在持有锁之后,在执行业务逻辑过程中,他正准备删除锁,而且已经走到了条件判断的过程中,比如他已经拿到了当前这把锁确实是属于他自己的,正准备删除锁,但是此时他的锁到期了。那么此时线程2进来,但是线程1他会接着往后执行,当他卡顿结束后,他直接就会执行删除锁那行代码,相当于条件判断并没有起到作用,这就是删锁时的原子性问题。
之所以有这个问题,是因为线程1的拿锁,比锁,删锁,实际上并不是原子性的
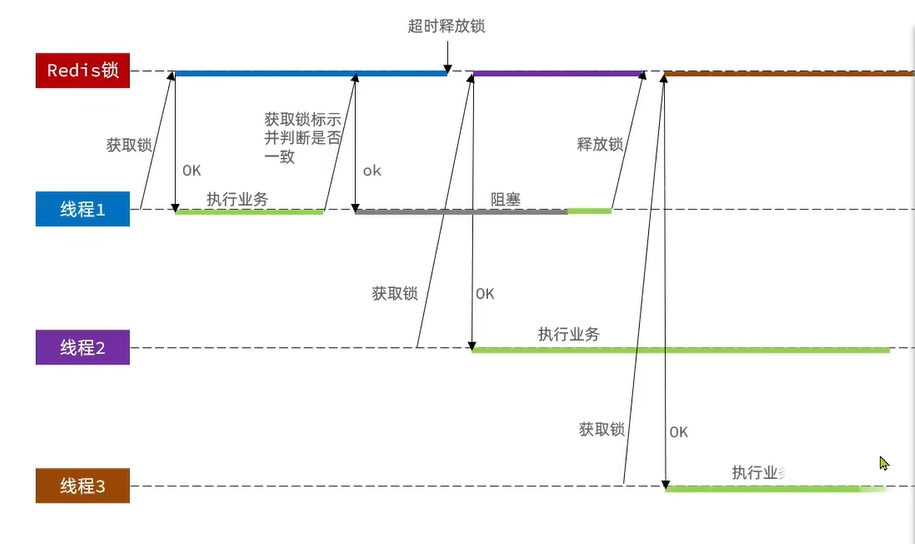
Lua脚本解决多条命令原子性问题
我们想要比较锁和删除锁的操作具有原子性,就需要用到Lua脚本
Lua是一种编程语言,它的基本语法大家可以参考网站:https://www.runoob.com/lua/lua-tutorial.html
这里不对Lua语言进行深究,只学习怎么写Lua去操作Redis,保证原子性
- Redis提供的调用函数
1 | redis.call('命令名称', 'key', '其它参数', ...) |
- 在Redis中使用
EVAL调用脚本,例如下面的脚本可以添加name-Rose,age-12两个key-value
1 | EVAL "return redis.call('set',KEYS[2],ARGV[2])" 2 name age Rose 12 |
- key类型参数会放入
KEYS数组,其它参数会放入ARGV数组,在脚本中可以从KEYS和ARGV数组获取这些参数 - 调用函数和参数类型间的数字代表脚本想要的key类型的参数个数
回顾释放锁的业务流程:
获取锁中的线程标识
判断是否与指定的标示(当前线程标示)一致
如果一致则释放锁(删除)
如果不一致则什么都不做
对应的Lua脚本
1 | if(redis.call('get',KEYS[1]) == ARGV[1]) then |
利用Java代码调用Lua脚本改造分布式锁
在RedisTemplate中有这样一个方法,对应着EVAL命令
1 | /* |
在IDEA中下载EmmyLua插件方便写Lua脚本代码,并插件unlock.lua文件,写入代码
Lua脚本为一个文件,到用的时候才初始化读取是不应该的,我们应该事先读取好,所以可以使用static在类加载时静态初始化
1 | public static final DefaultRedisScript<Long> UNLOCK_SCRIPT; |
修改unlock()方法,取代原先代码,可以看到使用Lua脚本就只有一行代码,很好的保证了原子性
1 | public void unlock() { |
到此,我们就实现了一个生产可用、相对完善的锁了。
小总结
基于Redis的分布式锁实现思路:
- 利用
set nx ex获取锁,设置过期时间,保存线程标识 - 释放锁现判断线程标识是否与自己的一致,避免锁误删
特性:
- 利用
set nx满足互斥性 - 利用
set ex保证故障时锁仍能释放,避免死锁 - 利用
Lua脚本保证释放锁的原子性 - 利用Redis集群保证高可用和高并发
分布式锁-Redisson
Redisson: Easy Redis Java client and Real-Time Data Platform是 Redis Java 客户端和实时数据平台。
Redisson 对象提供了关注点分离,使您可以专注于数据建模和应用程序逻辑。
基于setnx实现的分布式锁存在的问题
重入问题:获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁,比如HashTable这样的代码中,他的方法都是使用synchronized修饰的,假如他在一个方法内,调用另一个方法,那么此时如果是不可重入的,不就死锁了吗?所以可重入锁他的主要意义是防止死锁,我们的synchronized和Lock锁都是可重入的。
不可重试:是指目前的分布式只能尝试一次,我们认为合理的情况是:当线程在获得锁失败后,他应该能再次尝试获得锁。
超时释放:我们在加锁时增加了过期时间,这样的我们可以防止死锁,但是如果卡顿的时间超长,虽然我们采用了lua表达式防止删锁的时候,误删别人的锁,但是毕竟没有锁住,有安全隐患
主从一致性: 如果Redis提供了主从集群,当我们向集群写数据时,主机需要异步的将数据同步给从机,而万一在同步过去之前,主机宕机了,就会出现死锁问题。
使用现成的分布式锁工具Redisson可以很好的解决这些问题

Redisson快速入门
在pom中引入Redisson依赖
1 | <!-- Redission--> |
创建RedissonConfig类,完成Redisson中redis的连接配置
1 | /** |
使用Redisson创建的锁代替我们写的SimpleRedisLock
1 |
|
1 | // 创建锁对象 |
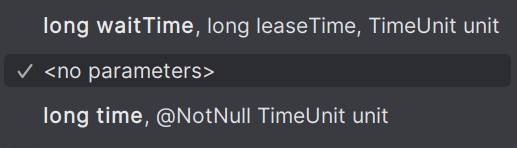
其中Redisson的tryLock()方法中可以接收三个参数,分别为获取锁的最大等待时间,锁自动释放时间,时间单位
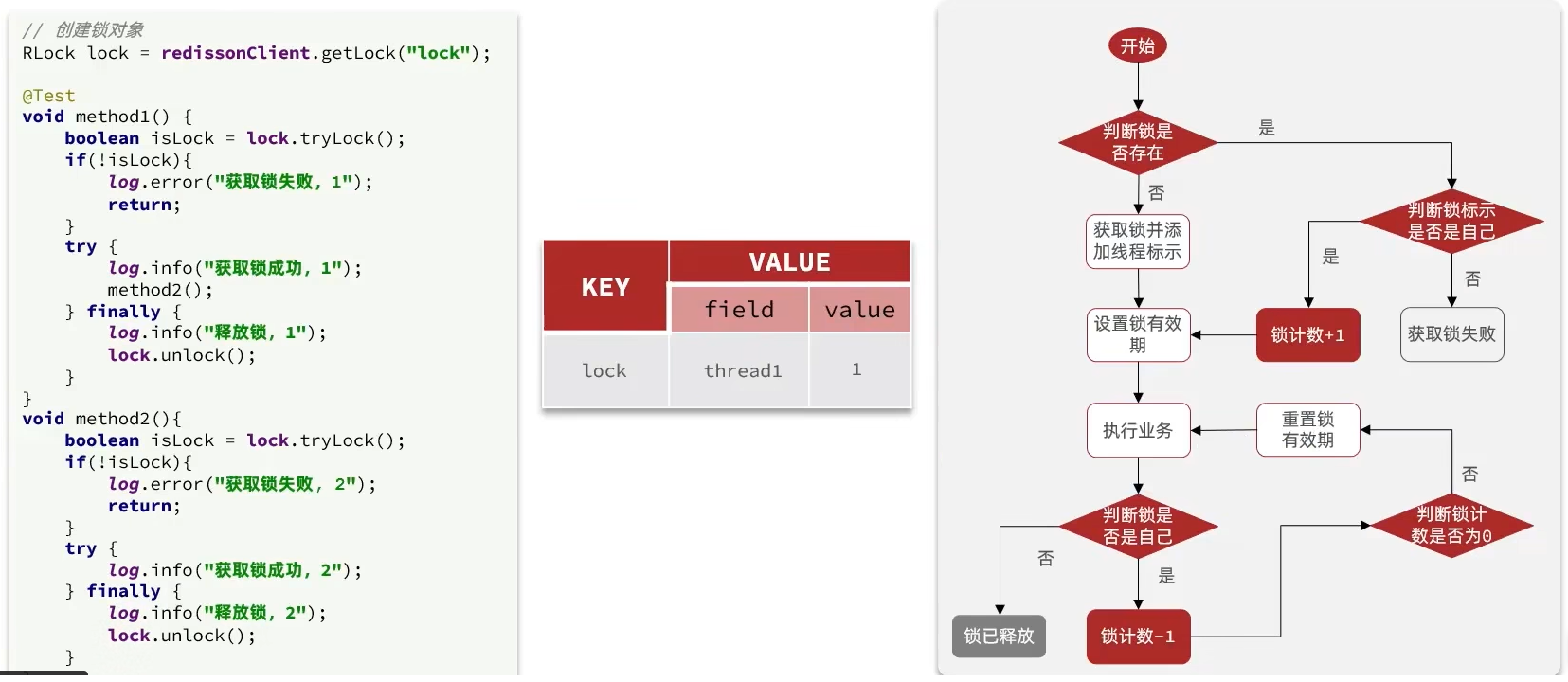
Redisson可重入锁原理
在分布式锁中,他采用hash结构用来存储锁,其中key表示表示这把锁是否存在,用field表示当前这把锁被哪个线程持有
流程图如下,需要注意的是值为0才可以释放锁,不为0时要刷新时间
获取锁的Lua脚本
1 | local key = KEYS[1]; --锁的key |
释放锁的Lua脚本
1 | local key = KEYS[1]; --锁的key |
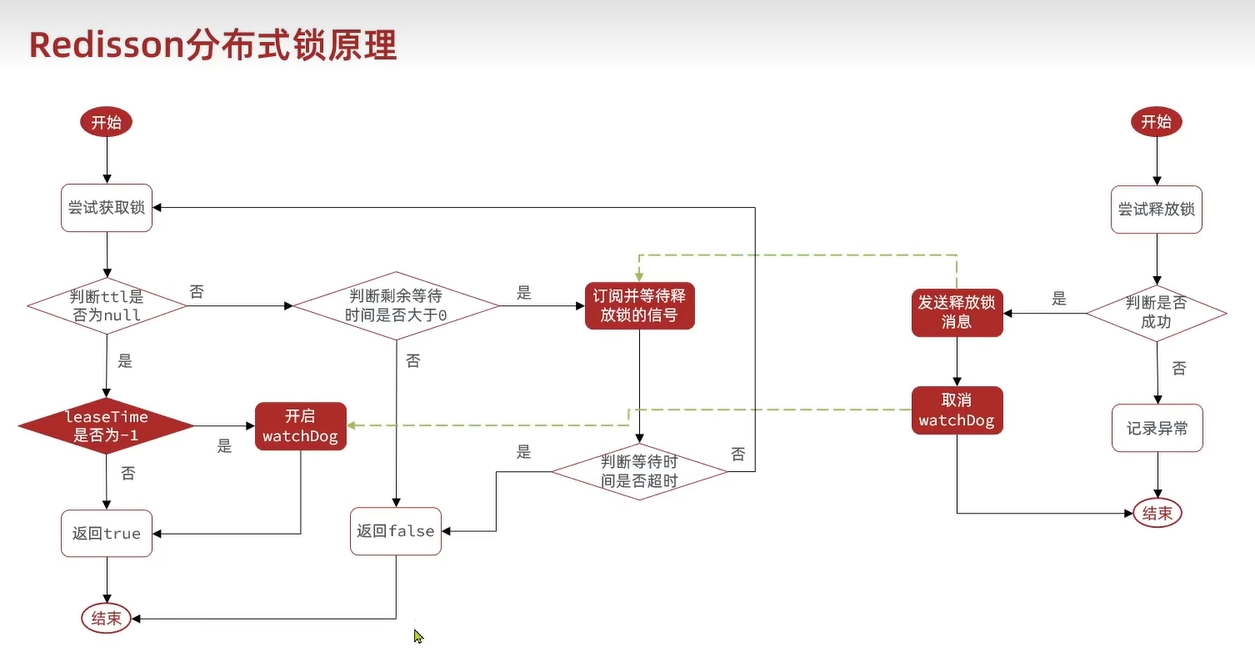
Redission锁重试和WatchDog机制
重试:在第一次尝试锁失败以后,不会立刻失败,而是去做一个等待,去订阅和等待释放锁的消息,利用PubSub锁的机制实现等待、唤醒,在其他线程释放锁的时候会去发送一条锁已可用的消息,可以被等待的线程捕获到,那么就可以重新获取锁了,再次获取又失败了又继续等待。当然不是无限次尝试,会有一个等待的时间,如果说超过了这个时间,就不重试了。
锁超时释放:在没有传入过期时间时,在获取锁成功后会由WatchDog开启一个定时任务,每隔一段时间就会去重置锁的有效时间,那么锁的时间就会重新计时
watchdog的默认过期时间为30秒,而规定了刷新时间为internalLockLeaseTime / 3
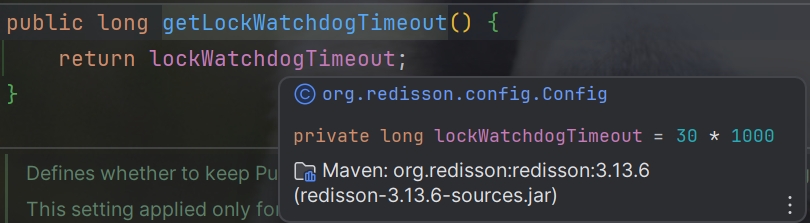
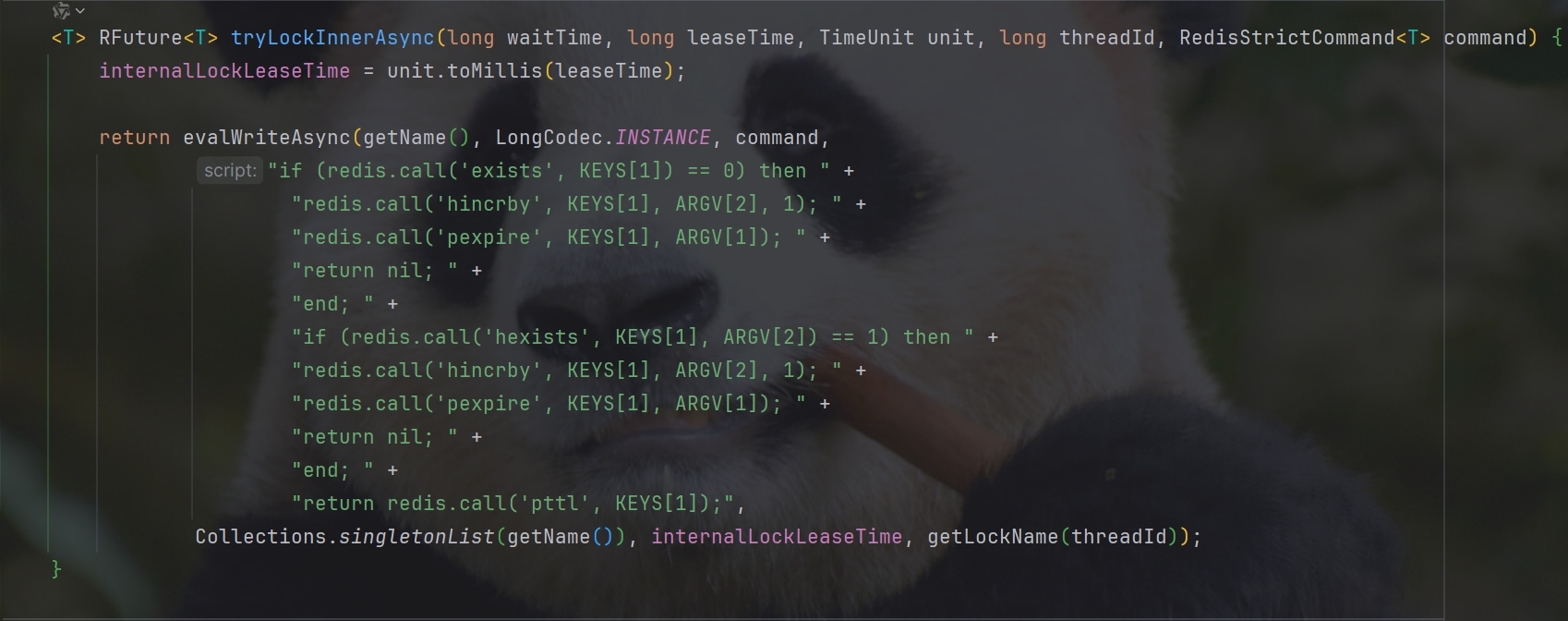
Redisson源码中的Lua脚本:
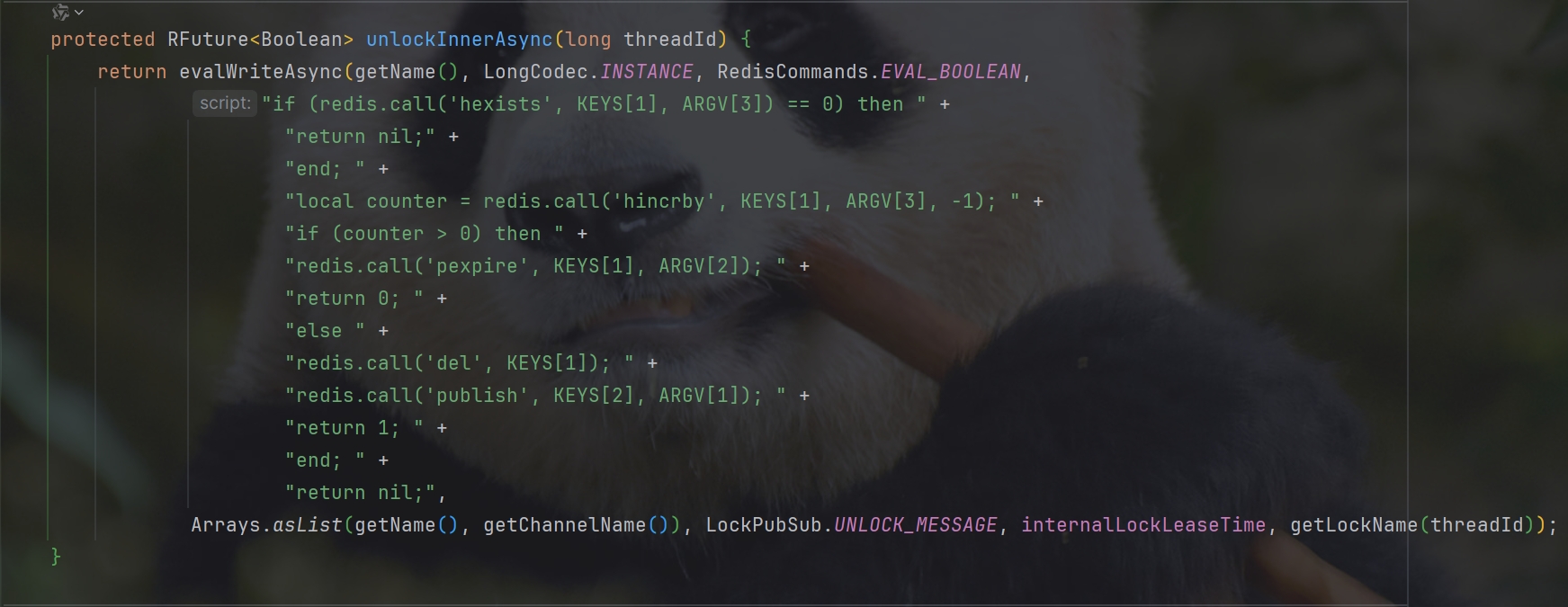
在释放锁的Lua脚本中redis.call('publish', KEYS[2], ARGV[1]); 会向订阅者发送锁已经释放的消息,那么订阅者就可以试着拿锁
如果是没有传入时间,则此时也会进行抢锁, 而且抢锁时间是默认看门狗时间 commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout()
ttlRemainingFuture.onComplete((ttlRemaining, e) 这句话相当于对以上抢锁进行了监听,也就是说当上边抢锁完毕后,此方法会被调用,具体调用的逻辑就是去后台开启一个线程,进行续约逻辑,也就是看门狗线程
1 | RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(waitTime, |
此逻辑就是续约逻辑,注意看commandExecutor.getConnectionManager().newTimeout() 此方法
Method( new TimerTask() {},参数2 ,参数3 )
指的是:通过参数2,参数3 去描述什么时候去做参数1的事情,现在的情况是:10s之后去做参数一的事情
因为锁的失效时间是30s,当10s之后,此时这个timeTask 就触发了,他就去进行续约,把当前这把锁续约成30s,如果操作成功,那么此时就会递归调用自己,再重新设置一个timeTask(),于是再过10s后又再设置一个timerTask,完成不停的续约
假设我们的线程出现了宕机,因为没有人再去调用renewExpiration这个方法,所以等到时间之后自然就释放了,也不会尝试死锁问题
WatchDog
在Redisson的源码中,拿到锁之后开启watchdog(看门狗)更新有效期的主要原因是为了防止由于锁过期而导致的锁丢失问题,从而确保锁的可靠性。具体原因如下:
- 自动续期:当一个线程获取到分布式锁时,会设置一个初始的过期时间。如果在锁持有期间,该线程由于某些原因(例如长时间的业务处理、网络延迟等)未能及时释放锁,那么锁就有可能在过期后自动释放,从而被其他线程获取。为了避免这种情况,Redisson引入了watchdog机制。
- 保持锁的有效性:watchdog会定期(默认每隔30秒)检查并延长锁的过期时间,确保在锁持有期间锁不会意外释放。这样,即使业务处理时间较长,也能保证锁一直由当前线程持有,不会被其他线程误抢。
- 防止死锁:虽然watchdog能有效延长锁的持有时间,但也设置了一个锁的最大持有时间(默认为30分钟)。即使出现了极端情况,比如持有锁的线程发生了故障,也能通过这个机制防止死锁的发生,确保系统的健壮性。
Redisson中watchdog机制的实现原理如下:
- 当一个线程获取到锁时,会启动一个看门狗定时任务。
- 该定时任务会定期检查当前线程是否仍然持有锁,如果是则续期。
- 续期操作会不断延长锁的有效期,直到锁被显式释放或者超过最大持有时间为止。
这个机制保证了在分布式环境中,锁能够更加可靠地被持有和释放,避免了由于锁过期导致的并发问题。
Redission锁的MutiLock
多个独立的Redis节点,必须在所有节点都重入锁,才算获取锁成功。简而言之,每个Redis节点都看看有没有这把锁,都有才行
- 以主从为例:我们去写命令,写在主机上, 主机会将数据同步给从机,但是假设在主机还没有来得及把数据写入到从机去的时候,此时主机宕机,哨兵会发现主机宕机,并且选举一个slave变成master,而此时新的master中实际上并没有锁信息,此时锁信息就已经丢掉了。
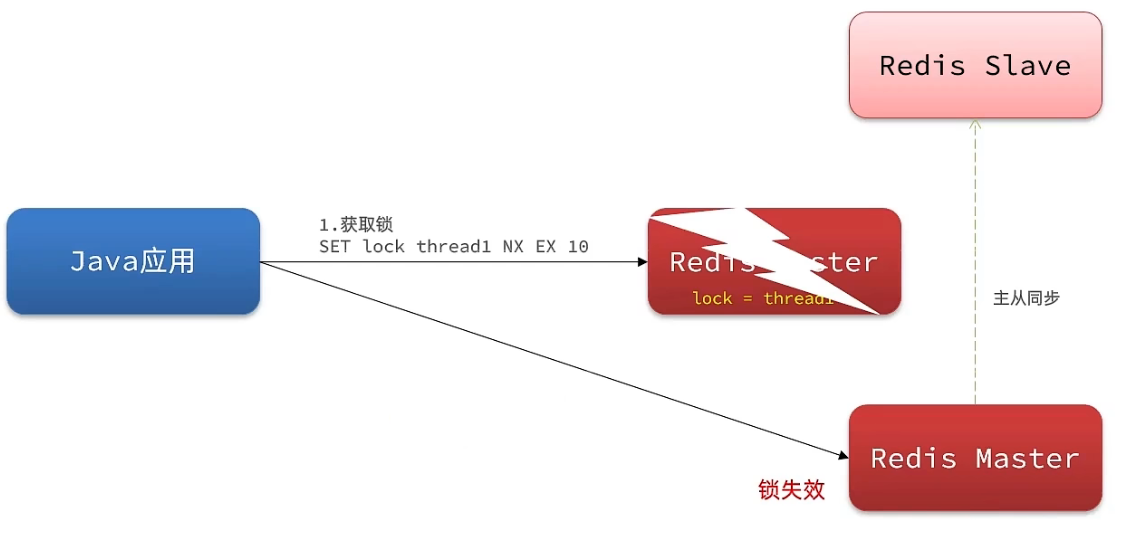
- 解决方法
Redission提出来了MutiLock锁,使用这把锁就不使用主从了,每个节点的地位都是一样的。
这把锁加锁的逻辑需要写入到每一个主丛节点上,只有所有的服务器都写入成功,此时才是加锁成功,假设现在某个节点挂了,那么他去获得锁的时候,只要有一个节点拿不到,都不能算是加锁成功,就保证了加锁的可靠性。
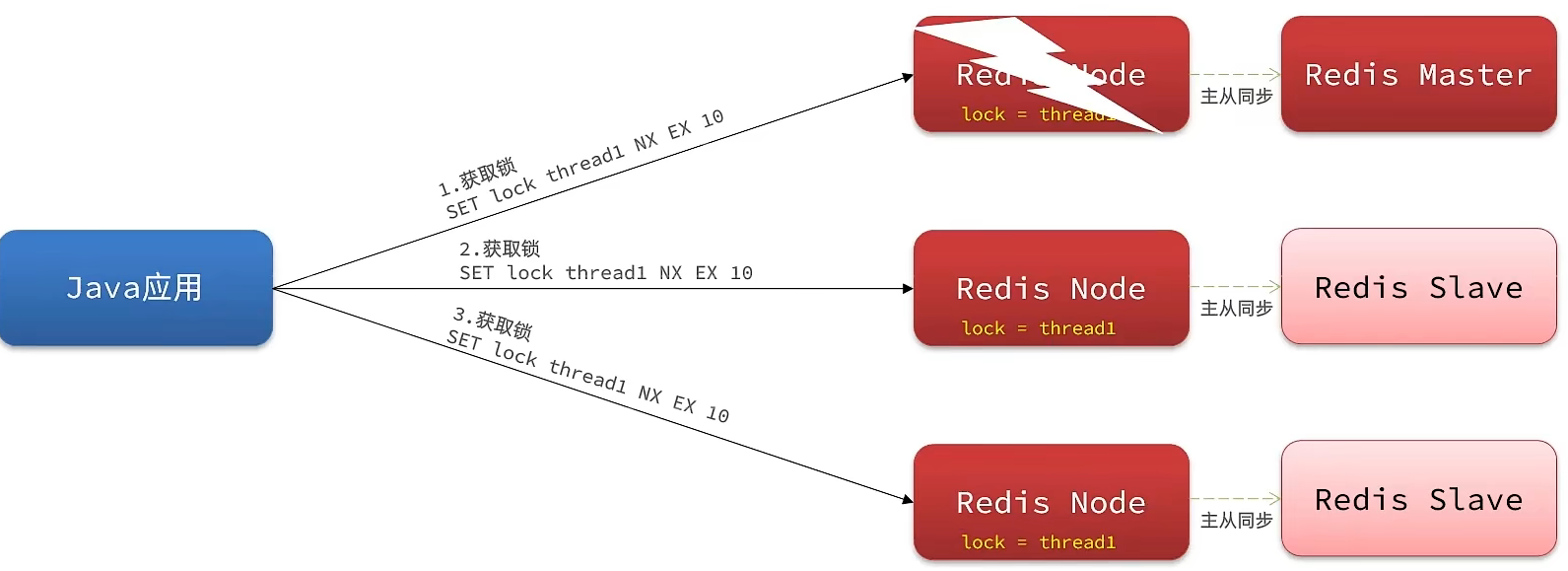
MutiLock(联锁)原理
multiLock 的核心思想是将多个锁组合在一起,以确保这些锁在同一个操作中被同时获取和释放。具体来说,multiLock 使用 ArrayList 存储每一个锁,并按照特定的逻辑依次尝试获取和释放这些锁。
- 创建 MultiLock 对象
首先,通过传入多个 RLock 对象来创建一个 RedissonMultiLock 实例。以下是一个简单的示例:
1 | RLock lock1 = redisson.getLock("lock1"); |
- 存储锁对象
RedissonMultiLock 内部使用一个 ArrayList 来存储传入的锁对象。这些锁对象会在获取和释放锁时被依次处理。
1 | private final List<RLock> locks = new ArrayList<>(); |
- 获取锁
multiLock 的 lock 方法会依次尝试获取所有存储在 ArrayList 中的锁。如果某一个锁获取失败,会释放已经获取的所有锁,并返回获取失败的状态。
在获取锁失败的时候还会对失败次数继续判断:
1 | locks.size() - acquiredLocks.size() == failedLocksLimit() |
failedLocksLimit 方法可能返回一个允许的锁获取失败的数量上限。例如,如果 failedLocksLimit 返回 1,表示在获取多个锁时,允许有一个锁获取失败。这个机制的主要目的可能是为了实现某种宽松的锁策略,在某些场景下,即使部分锁获取失败,也可以继续执行后续操作,即允许某个不太重要的资源锁获取失败。
- 释放锁
multiLock 的 unlock 方法会依次释放所有存储在 ArrayList 中的锁。
1 | public void unlock() { |
实现细节
- 顺序处理:获取和释放锁时,按照锁在
ArrayList中的顺序依次处理,确保每个锁的获取和释放都是有序的。 - 超时处理:在尝试获取多个锁时,会计算剩余的等待时间,确保在指定的时间内尝试获取所有锁。
- 失败处理:如果在获取锁的过程中任意一个锁获取失败,会释放已经获取的所有锁,以避免资源的死锁和浪费。
小总结
不可重入Redis分布式锁:
原理:利用setnx的互斥性;利用ex避免死锁;释放锁时判断线程标示
缺陷:不可重入,无法重试,锁超时失效,主从一致性问题

可重入的Redis分布式锁(Redisson):
原理
- 可重入:利用hash结构记录线程id和重入次数
- 可重试:利用信号量和PubSub功能实现等待、唤醒,获取锁失败的重试机制
- 超时续约:利用watchDog,每隔一段时间(releaseTime / 3),重置超时时间
- 主从一致性:使用Redisson的multiLock,采用多个独立的Redis节点,必须在所有节点都获取重入锁,才算获取锁成功
前三个容易出现缺陷:redis宕机引起锁失效问题
使用Redisson的multiLock的运维成本高,实现复杂
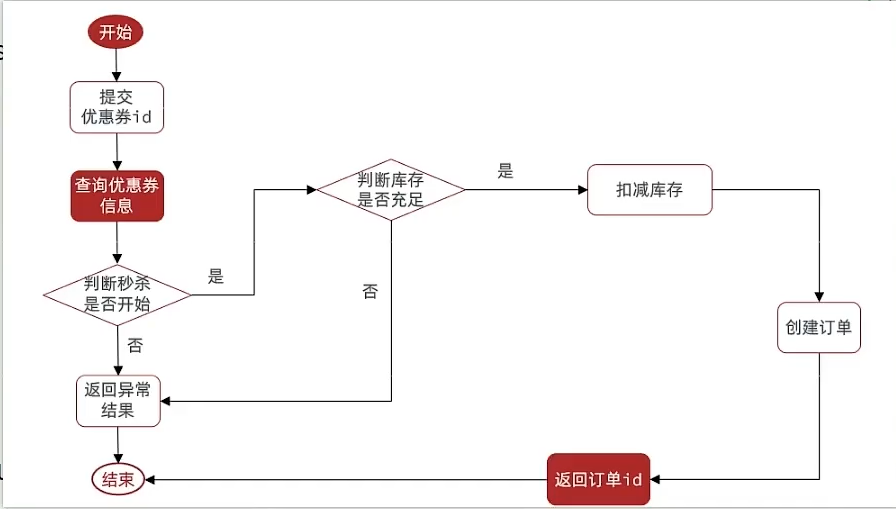
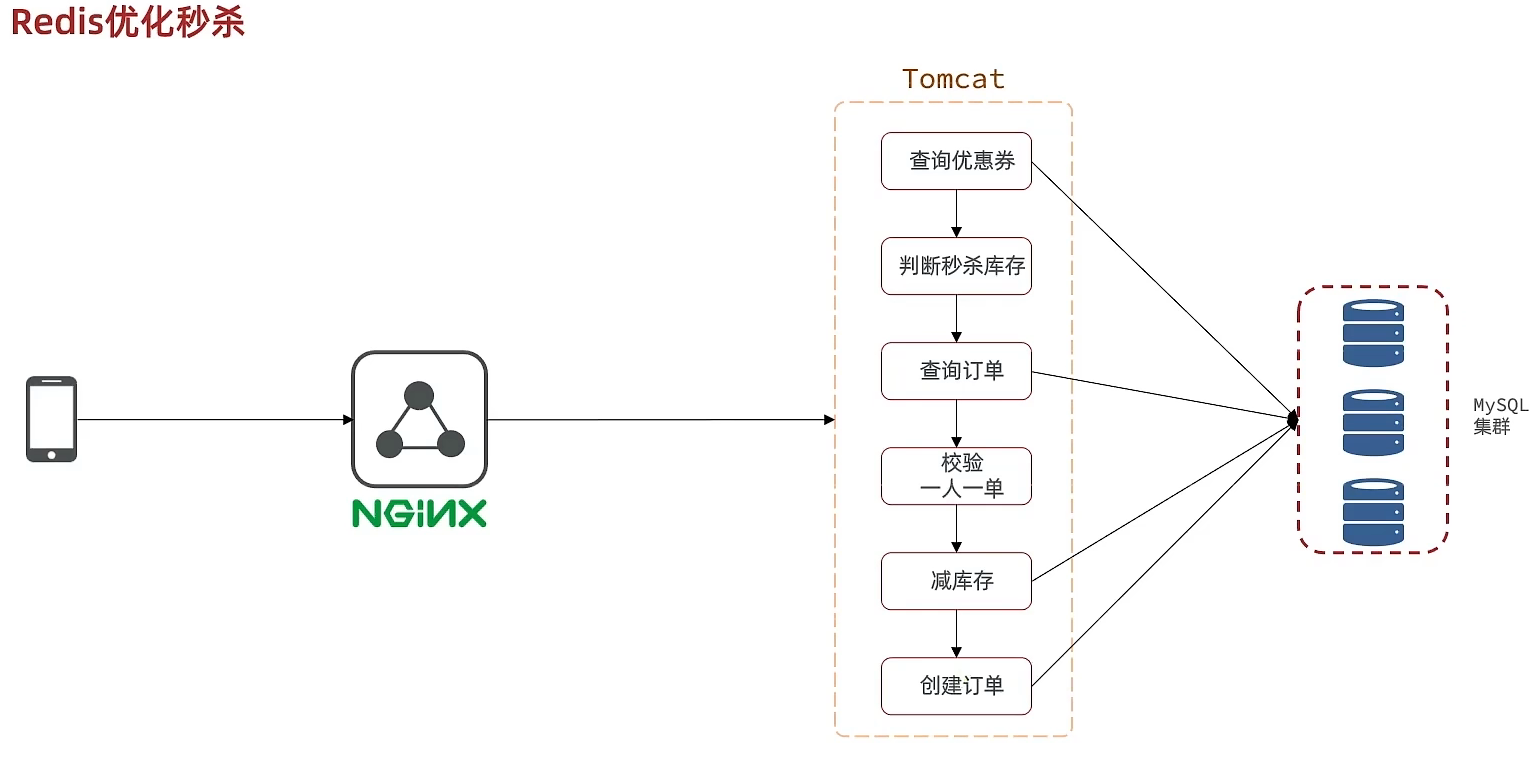
Redis秒杀优化
之前的秒杀流程图如下,6个过程是串行执行的,并且有4个过程是需要操作到数据库的,甚至最后两个过程还是数据库的写操作
优化方案:我们将耗时比较短的逻辑判断放入到redis中,比如是否库存足够,比如是否一人一单,这样的操作,只要这种逻辑可以完成,就意味着我们是一定可以下单完成的,我们只需要进行快速的逻辑判断,根本就不用等下单逻辑走完,我们直接给用户返回成功, 再在后台开一个线程,后台线程慢慢的去执行queue里边的消息,这样程序不就超级快了吗?而且也不用担心线程池消耗殆尽的问题,因为这里我们的程序中并没有手动使用任何线程池
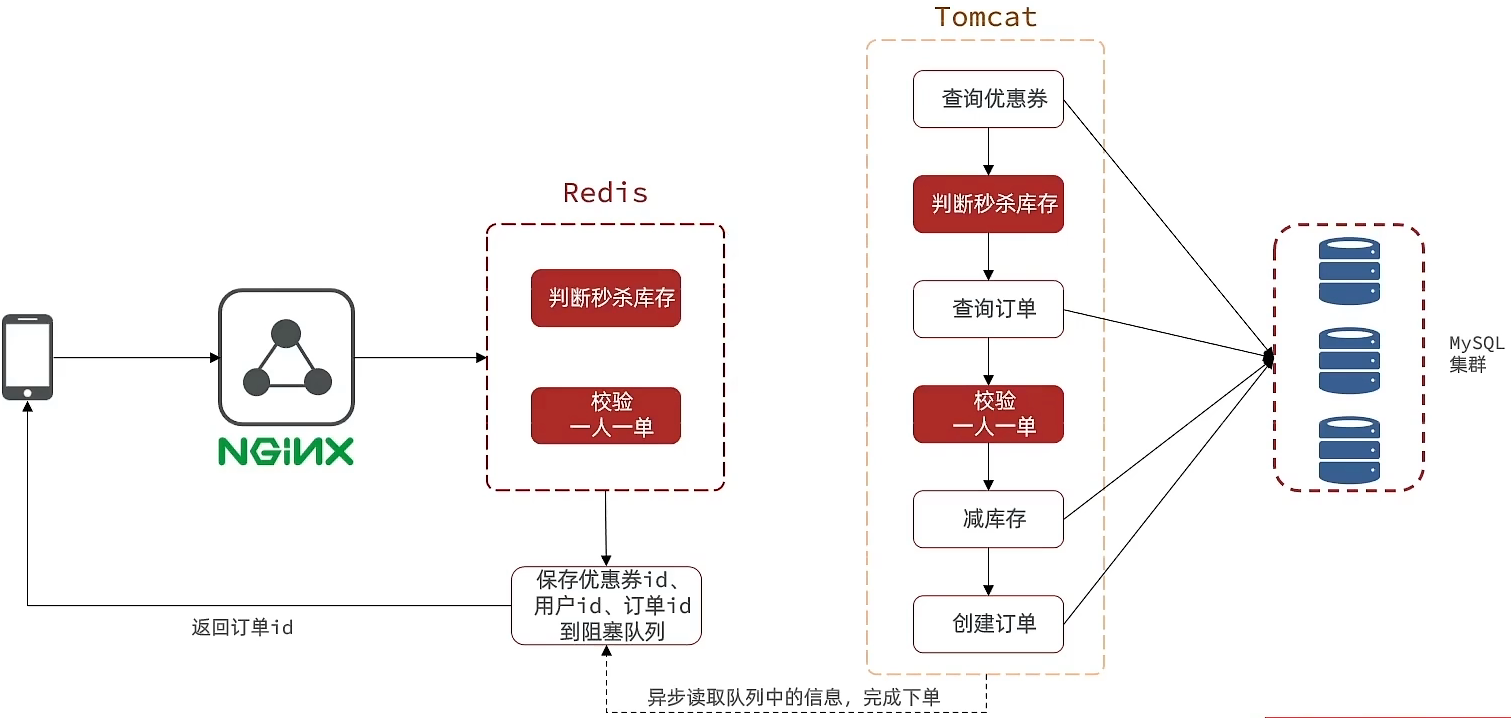
难点1:是我们怎么在redis中去快速校验一人一单,还有库存判断
难点2:是由于我们校验和tomct下单是两个线程,那么我们如何知道到底哪个单他最后是否成功,或者是下单完成,为了完成这件事我们在redis操作完之后,我们会将一些信息返回给前端,同时将这些信息丢到异步queue中去,后续操作中,可以通过这个id来查询我们tomcat中的下单逻辑是否完成了。
秒杀优化实现思路
根据Lua脚本中不同的返回值完成业务的判断,开启新线程进行异步下单
库存使用String类型存储,实现自减;下单的用户id存入Set集合,具有不可重复的特性
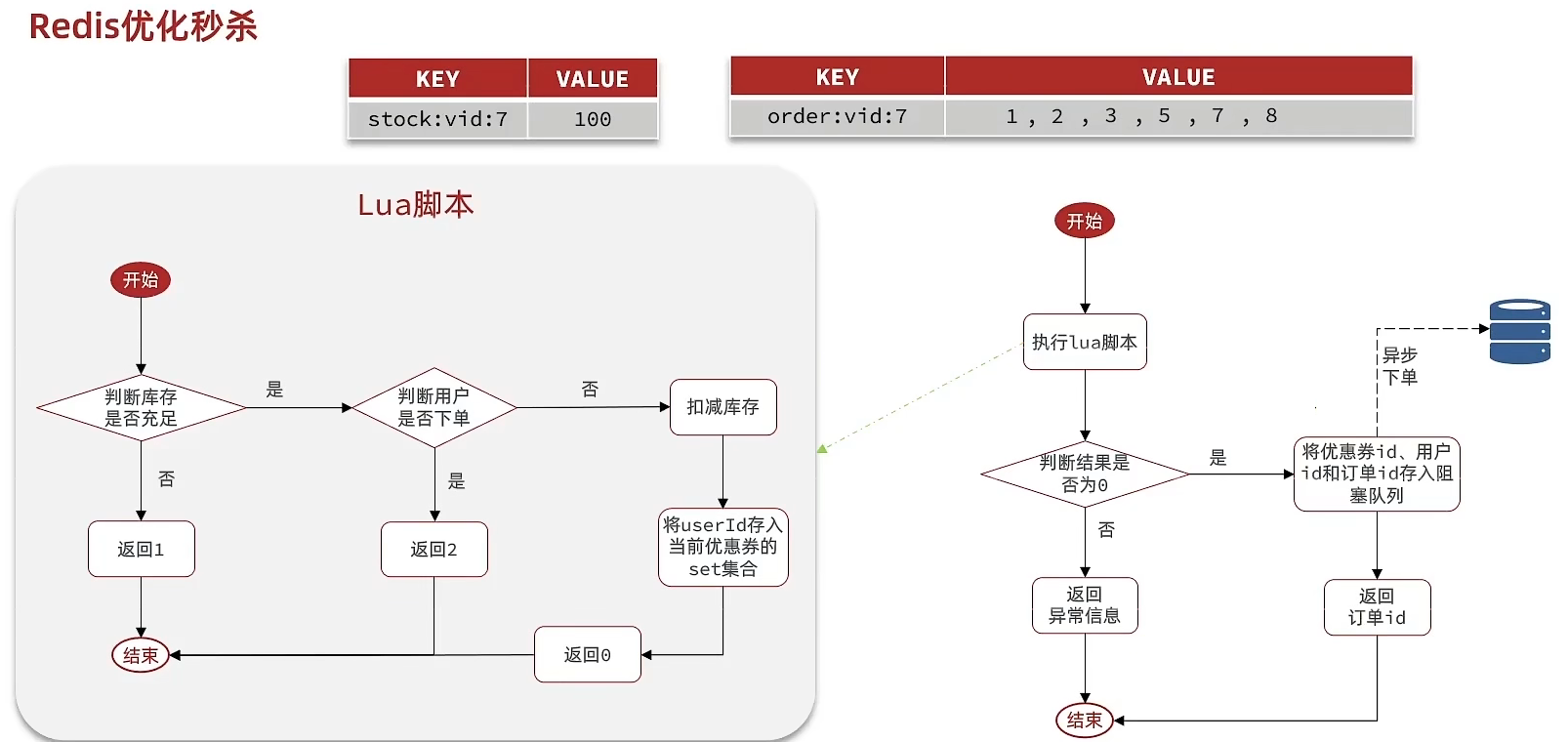
Redis完成库存存储和秒杀资格判断
需求:
新增秒杀优惠券的同时,将优惠券信息保存到Redis中
基于Lua脚本,判断秒杀库存、一人一单,决定用户是否抢购成功
如果抢购成功,将优惠券id和用户id封装后存入阻塞队列
开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
新建秒杀优惠券时同步写入Redis
1 |
|
基于Lua脚本判断库存和一人一单
1 | -- 1.参数列表 |
完善业务代码并进行测试
1 |
|
到Navicat中检查Redis,确认Lua脚本执行无误

至此,我们完成了前两步,接下来继续完成后两步
基于阻塞队列完成异步秒杀优化
我们继续实现后两步
如果抢购成功,将优惠券id和用户id封装后存入阻塞队列
开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
创建阻塞队列
1 | private BlockingQueue<VoucherOrder> orderTasks = new ArrayBlockingQueue<>(1024 * 1024); |
创建异步线程池
1 | public static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor(); |
定义proxy为变量,与ThreadLocal同理,拿不到代理对象,只能给值
1 | private IVoucherOrderService proxy; |
修改前两步未完成seckillVoucher()方法,补上放入阻塞队列的代码,并获取代理对象赋值
1 | // 创建订单ID,封装订单信息 |
@PostConstruct注解在类加载时执行,死循环一致尝试读取阻塞队列
1 |
|
修改订单处理代码,其中的锁代码可以省略,Redis已经判断过了
1 | private void handleVoucherOrder(VoucherOrder voucherOrder) { |
修改创建订单代码
1 |
|
小总结
秒杀业务的优化思路
- 先利用Redis完成库存余量、一人一单判断,完成抢单业务
- 再将下单业务放入阻塞队列,利用独立线程异步下单
- 基于阻塞队列的异步秒杀存在哪些问题?
- 内存限制问题(手动设置了阻塞队列的长度,容易溢出)
- 数据安全问题
- 数据存储在Redis中,宕机后数据丢失。
- 阻塞队列存在JVM中,JVM宕机时阻塞队列全部订单信息会丢失
Redis消息队列
消息队列:存放消息的队列
- 消息队列:存储和管理消息,也被称为消息代理(Message Broker)
- 生产者:发送消息到消息队列
- 消费者:从消息队列获取消息并处理消息
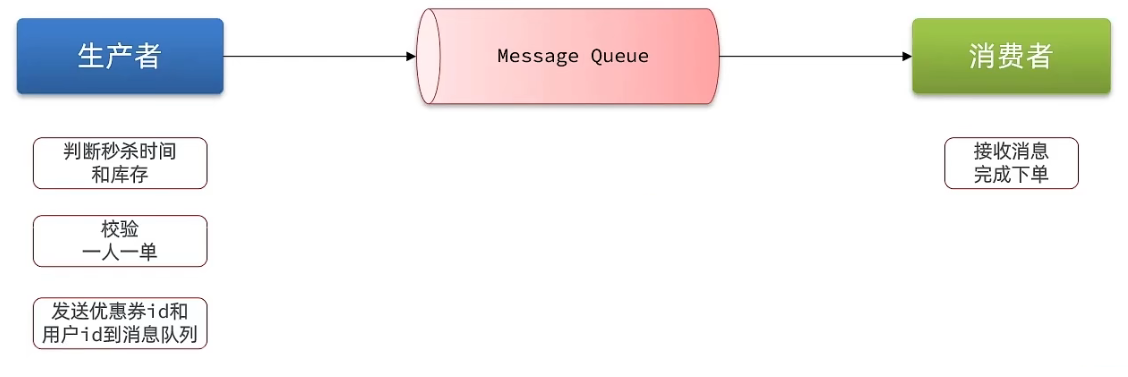
使用队列的好处在于解耦:快递员会把快递放到菜鸟驿站,然后再由菜鸟驿站通知您的快递到达菜鸟了,而快递员无需等待,就可以去送下一批货,而不是说你不在家就一直等你。
由于这门课是学习Redis的,所以我们使用Redis实现消息队列,对于中小型企业或者不是大型项目,Redis已经足够了。
如果要求更高的话,可以使用RabbitMQ: One broker to queue them all或者Apache Kafka,功能更加强大,可以去学习2024最新SpringCloud微服务开发与实战,java黑马商城项目微服务实战开发(涵盖MybatisPlus、Docker、MQ、ES、Redis高级等)
基于List实现的消息队列
Redis的list数据结构是一个双向链表,很容易模拟出队列效果。搭配LPUSH和RPOP或者RPUSH和LPOP就好了
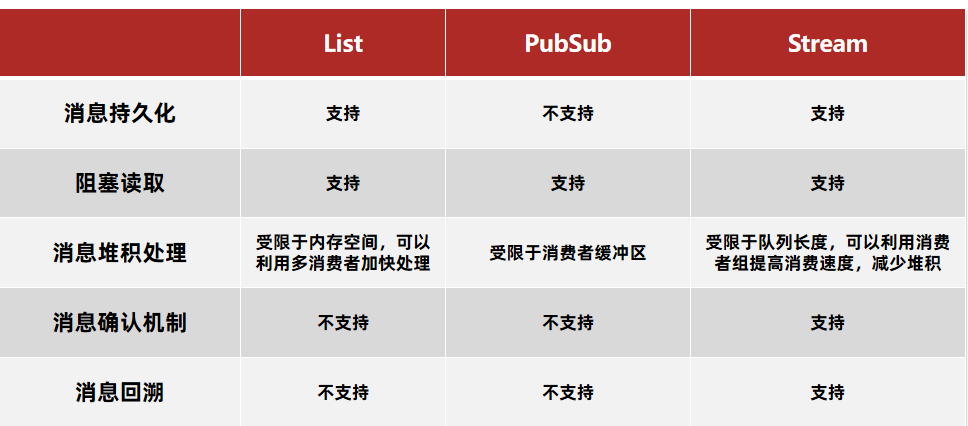
基于List的消息队列有哪些优缺点?
优点:
- 利用Redis存储,不受限于JVM内存上限
- 基于Redis的持久化机制,数据安全性有保证
- 可以满足消息有序性
缺点:
- 无法避免消息丢失
- 只支持单消费者
基于PubSub实现的消息队列
PubSub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。Commands | Docs (PubSub)
SUBSCRIBE channel [channel]:订阅一个或多个频道PUBLISH channel msg:向一个频道发送消息PSUBSCRIBE pattern[pattern]:订阅与pattern格式匹配的所有频道- Supported glob-style patterns:
h?llosubscribes tohello,halloandhxlloh*llosubscribes tohlloandheeeelloh[ae]llosubscribes tohelloandhallo,but nothillo
- Supported glob-style patterns:
基于PubSub的消息队列有哪些优缺点?
优点:
- 采用发布订阅模型,支持多生产、多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
基于Stream的消息队列
Stream 是 Redis 5.0 引入的一种新数据类型,可以实现一个功能非常完善的消息队列。Commands | Docs (Stream)
XADD发送消息

XREAD读取消息

注意:当我们指定起始ID为$时,代表读取最新的消息,如果我们处理一条消息的过程中,又有超过1条以上的消息到达队列,则下次获取时也只能获取到最新的一条,会出现漏读消息的问题
STREAM类型消息队列的XREAD命令特点:
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
基于Stream的消息队列-消费者组
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。具备下列特点:

- 创建消费者组:
1 | XGROUP CREATE key groupName Id [MKSTREAM] |
key:队列名称
groupName:消费者组名称
ID:起始ID标示,$代表队列中最后一个消息,0则代表队列中第一个消息
MKSTREAM:队列不存在时自动创建队列
- 删除指定的消费者组
1 | XGROUP DESTORY key groupName |
- 给指定的消费者组添加消费者
1 | XGROUP CREATECONSUMER key groupname consumername |
- 删除消费者组中的指定消费者
1 | XGROUP DELCONSUMER key groupname consumername |
- 从消费者组读取消息:
1 | XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...] |
group:消费组名称
consumer:消费者名称,如果消费者不存在,会自动创建一个消费者
count:本次查询的最大数量
BLOCK milliseconds:当没有消息时最长等待时间
NOACK:无需手动ACK,获取到消息后自动确认
STREAMS key:指定队列名称
ID:获取消息的起始ID:
- “>”:从下一个未消费的消息开始
- 其它:根据指定id从pending-list中获取已消费但未确认的消息,例如0,是从pending-list中的第一个消息开始
逻辑伪代码:
1 | while(true){ |
STREAM类型消息队列的XREADGROUP命令特点:
- 消息可回溯
- 可以多消费者争抢消息,加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制,保证消息至少被消费一次
各种方式实现消息队列的对比
基于Stream结构作消息队列,实现异步秒杀
实现步骤:
- 创建一个Stream类型的消息队列,名为stream.orders
- 修改之前的秒杀下单Lua脚本,在认定有抢购资格后,直接向stream.orders中添加消息,内容包含voucherId、userId、orderId
- 项目启动时,开启一个线程任务,尝试获取stream.orders中的消息,完成下单
- 在Redis中新建一个stream类型的消息队列

- 修改Lua脚本,添加两行代码
1 | -- 1.参数列表 |
- 修改操作Redis的代码,因为Lua中新增了将orderId需要传入,才能确保订单信息被存入消息队列时是完整的
1 |
|
- 修改单线程拿取消息队列中数据的代码,使用StringRedisTemplate中的opsForStream()方法操作Stream类型
1 |
|
- 新增handlePendingList()方法,处理已经读取消息但未ACK的情况,从pending-list中重新尝试拿到数据写入数据库并ACK
1 | private void handlePendingList() { |
执行代码检查无误,库存正常扣减,数据库写入正常,消息队列中保存了order消息
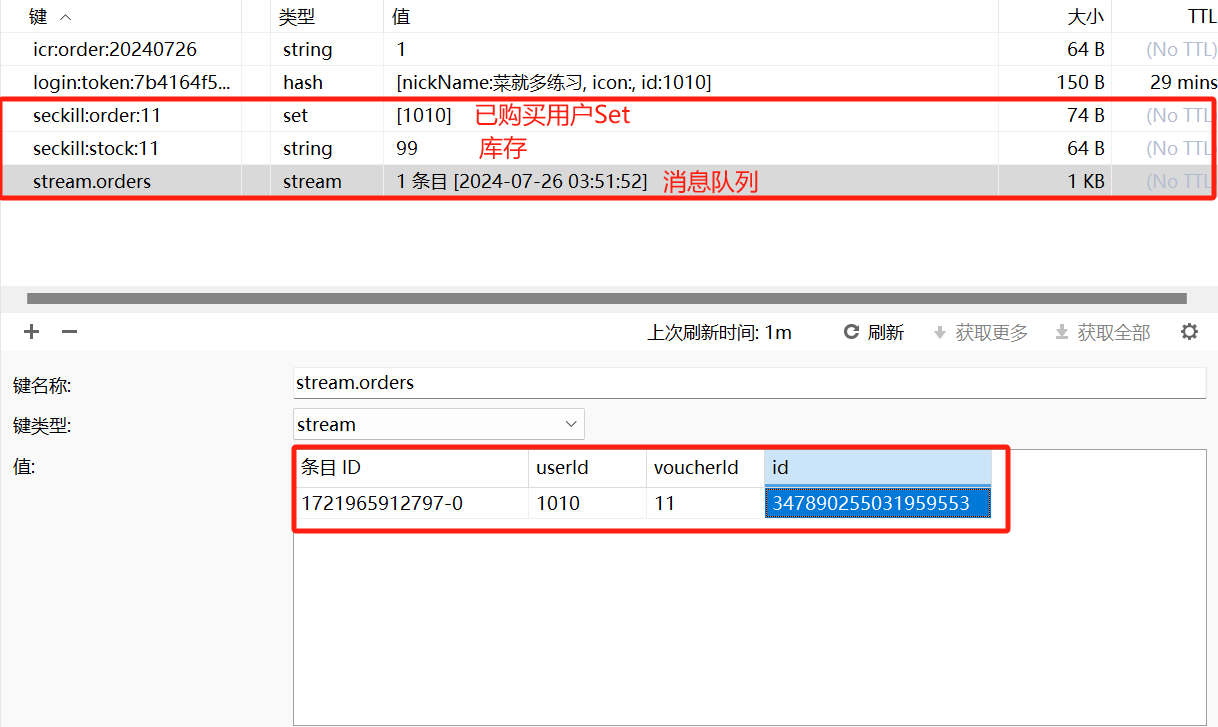
Redis消息队列中的订单ID与实际存入数据库中的一致


双 手 合 十 成 为 自 己 的 神
自 己 所 信 念 的 即 是 信 仰

微 信 号 : L I J J J W E I
Q Q 号 : 2 8 4 8 5 2 7 4 8 5




