使用 LLaMA-Factory 微调 Qwen2.5
使用 LLaMA-Factory 微调 Qwen2.5
实验环境
Windows11、Git
基座模型
- 去到 魔搭社区下载一个基座模型
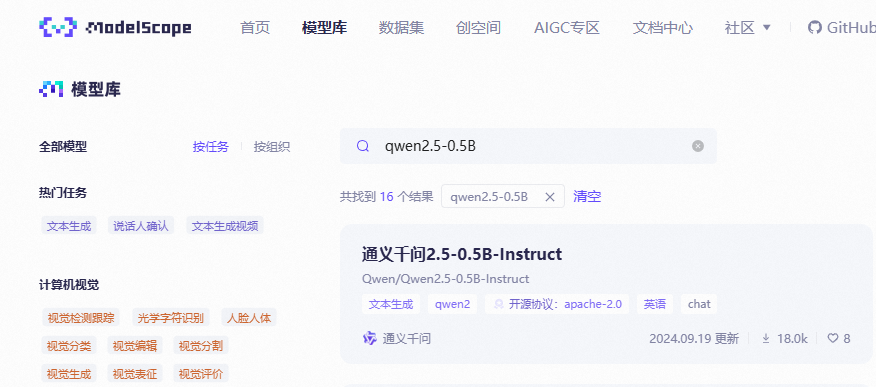
- 这里选择
Qwen/Qwen2.5-0.5B-Instruct,点进去,中间模型文件点击右边的下载模型下载到本地(下载方法自己选择)
LLaMA-Factory框架
安装
到LLaMA-Factory的仓库下载LLaMA-Factory,中文手册README_zh.md
1 | git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git |
注意:如果是有GPU的需要自己去pytorch官网下载带CUDA的torch,否则怎么安装都是CPU版本的
准备训练数据
建立自己的数据集JSON格式文件,训练需要有固定的JSON格式
我使用的是Alpaca格式,类似于下面的JSON格式,但是还可以添加其他属性,我这里只是有简单的
instruction、input、output

具体数据格式细节可看LLaMA-Factory/data/README_zh.md
- 将训练数据
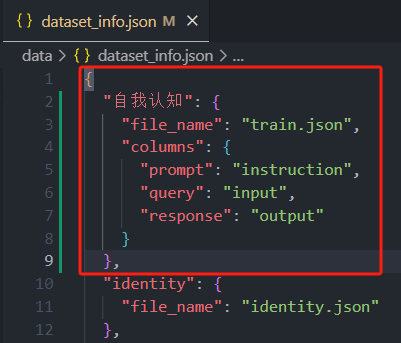
train.json放在data文件夹中 - 修改数据集描述文件:data文件夹中的
dataset_info.json文件,最上面加上你的数据集让他可以识别出来
启动Web UI
找到src文件夹下的webui.py,运行即可自动打开浏览器,看到LLaMA-Factory的WebUI
如果还缺少依赖自行安装
微调模型
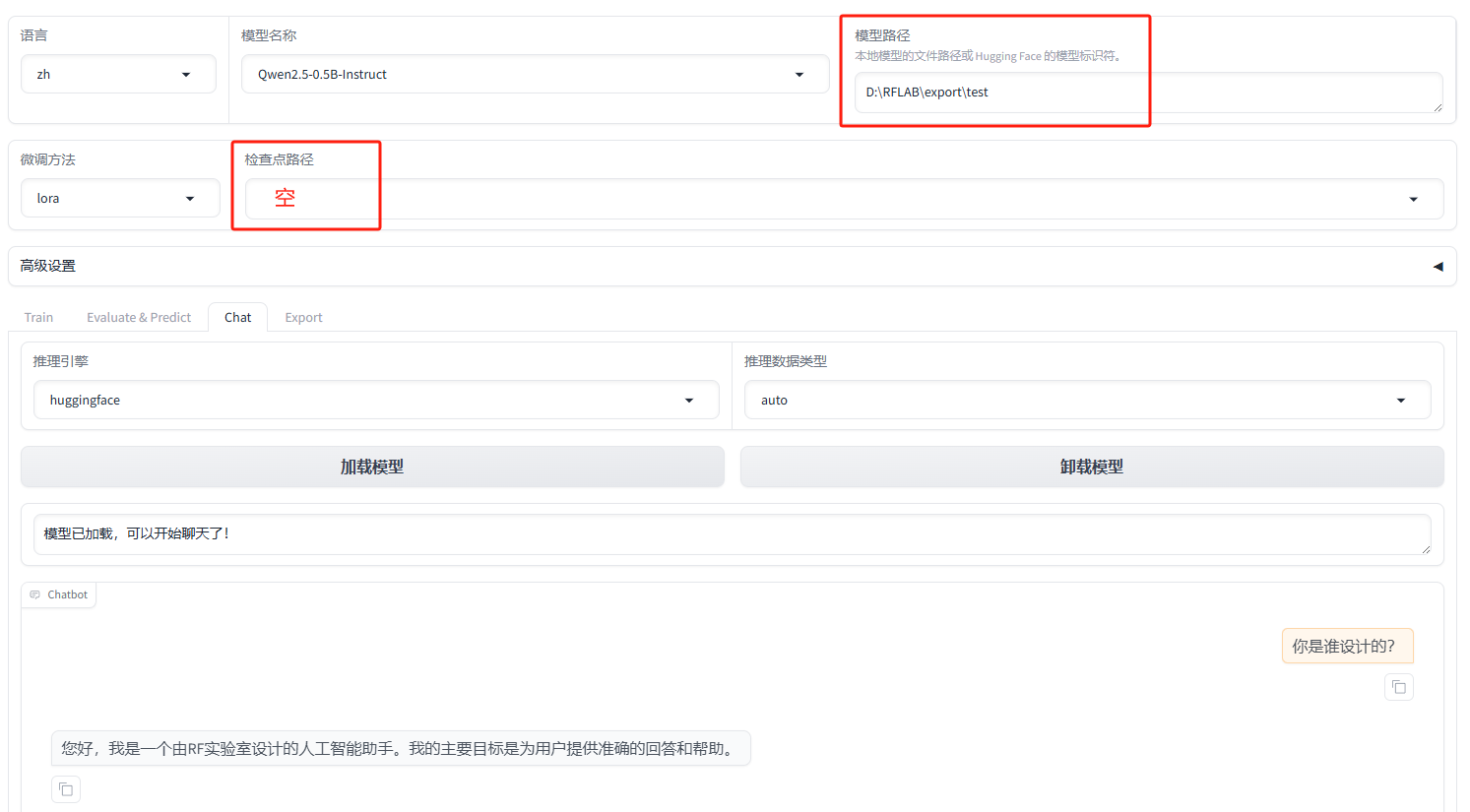
- 先选择语言为
zh,然后在模型名称处选择自己第一步下载的基座模型名称,再指定你模型下载的路径

推荐使用绝对路径,因为相对路径是相对于LLaMA-Factory文件夹的
- 为了测试模型路径是否选择正确,可以先到Chat处进行对话,证明模型加载成功
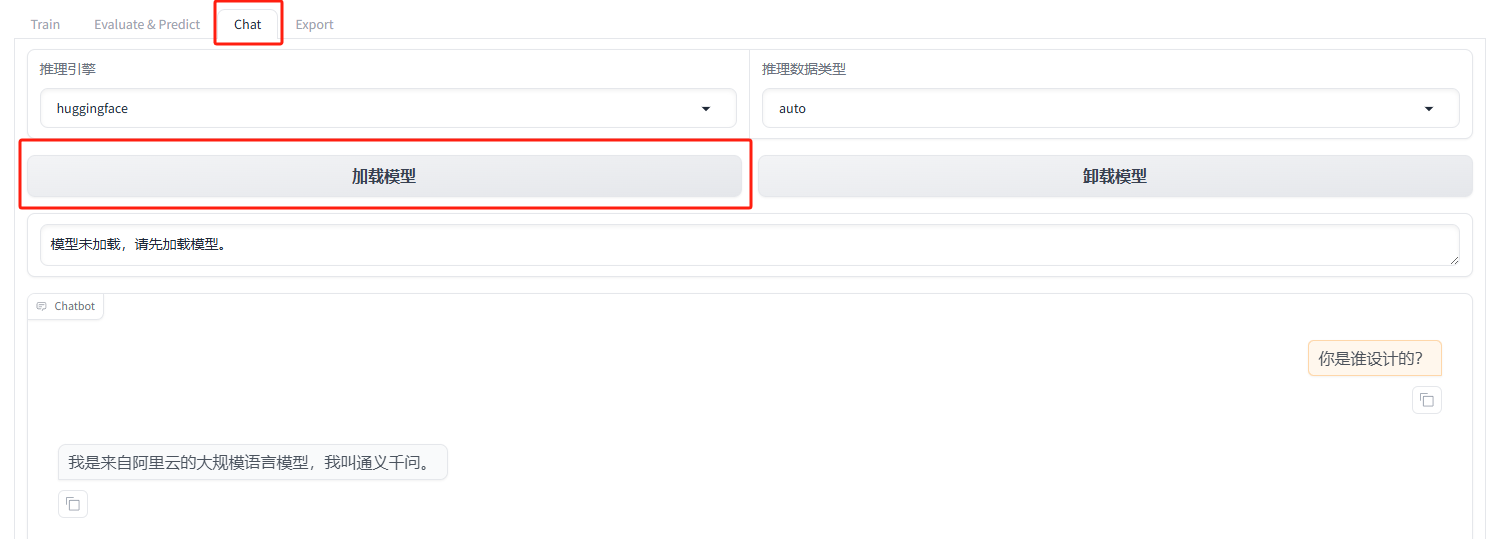
- 从Chat回到Train处,参数先不管(不懂),选择数据集,预览一下,可以看到数据出来证明成功

- 到下方,预览命令->保存训练参数->载入训练参数->开始,直接按顺序点过去

- 可以看到控制台中代码开始跑了,说明开始训练
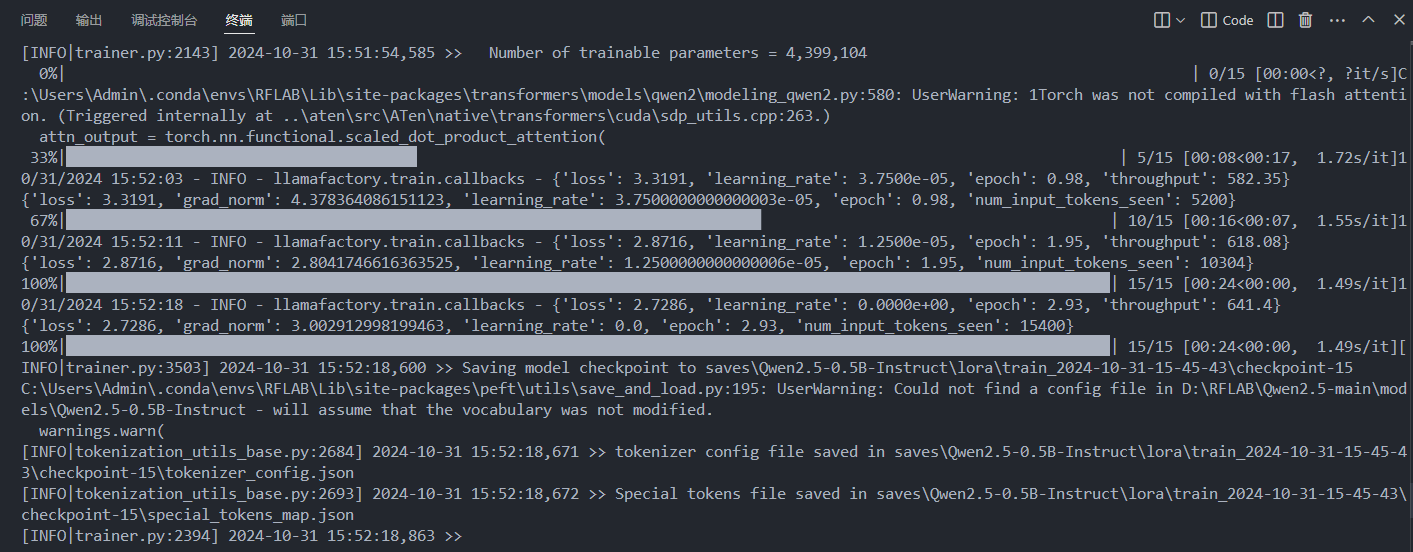
- 训练完毕,会出现提示和训练损失曲线
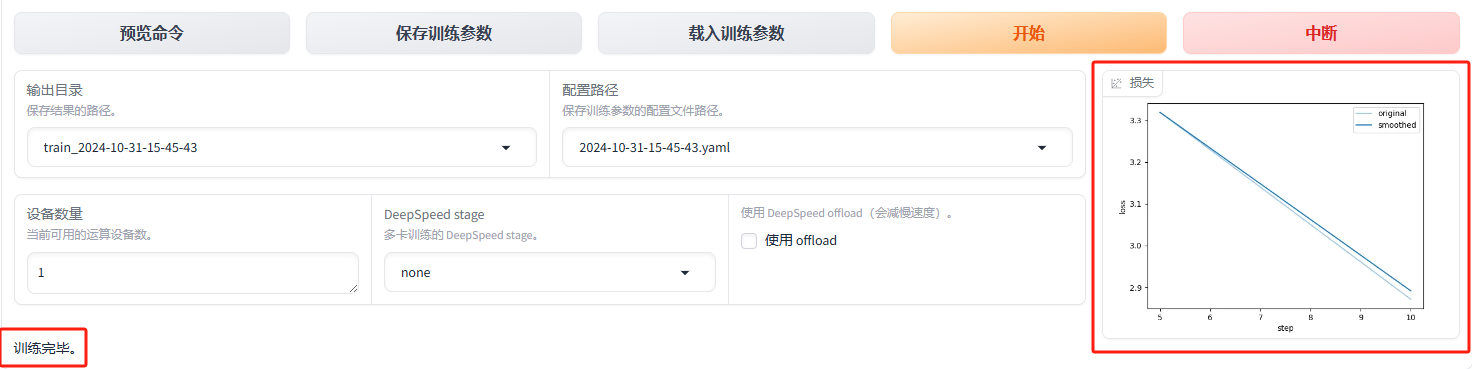
测试训练的模型
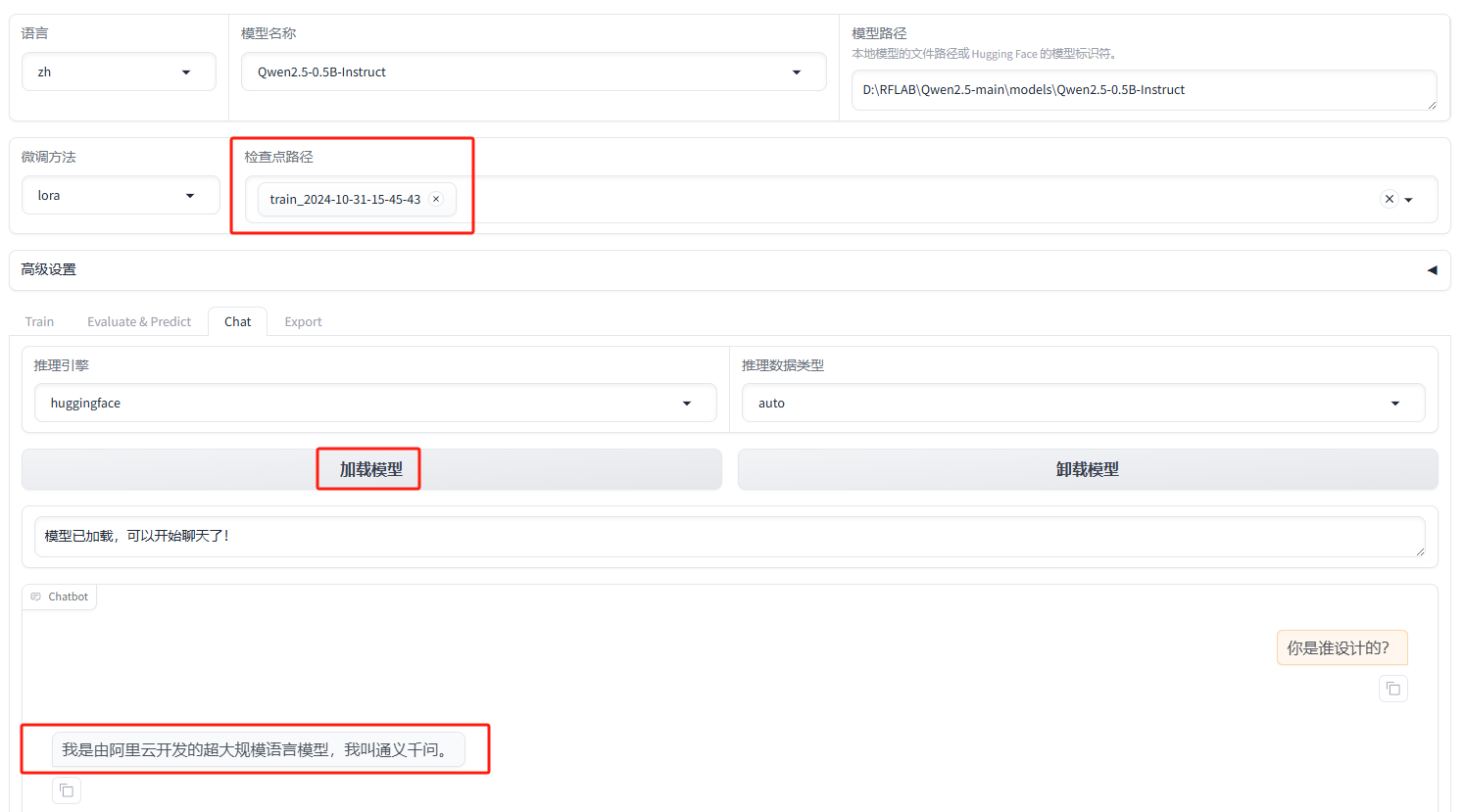
来到Chat处,选择检查点路径,这个检查点就相当于是我们的一个训练存档,选择刚刚训练的检查点
对话发现没有达到效果,他还叫通义千问,可能是由于我们训练的太少的问题
- 重新训练,降低学习率为4e-4(学慢点),然后加大训练轮数为10.0,重新加载新的检查点,这次效果达到了预期

实测降低学习率和加大轮数可以达到好一点的效果,第一次损失曲线知道了2.9以下,修正后可以到0.5以下,不懂原理,可能是这个原因
导出训练后的模型
- 训练好后我们可以导出模型,选择我们想要的检查点,检查点+基座模型=我们的模型
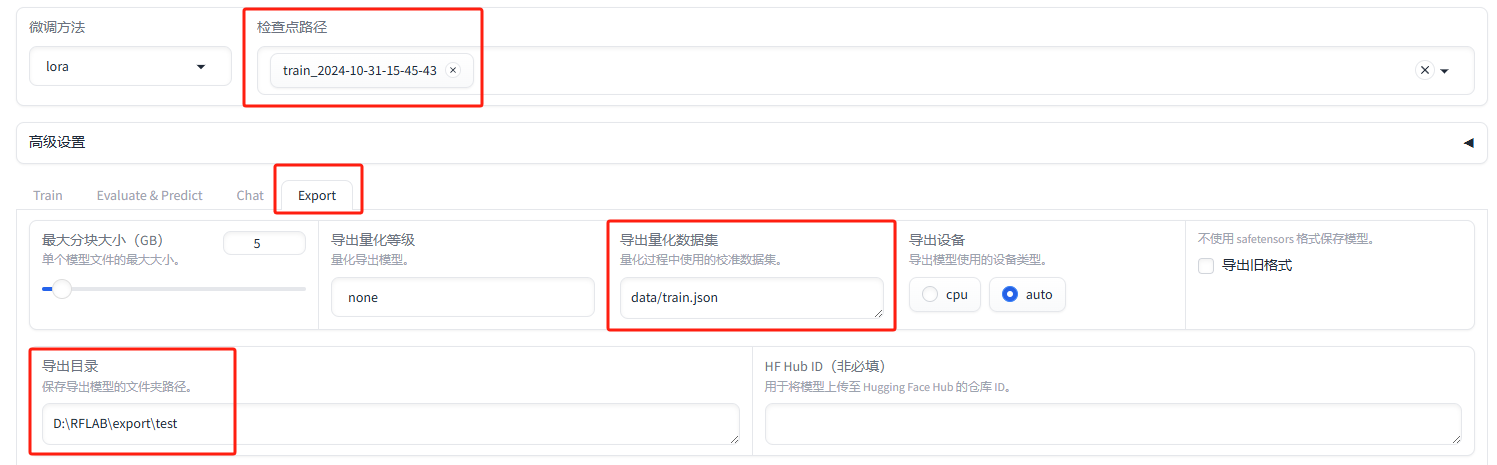
- 点击导出,导出后你可以发现他和我们的基座模型文件内容是一样的,因为导出本质上还是一个模型
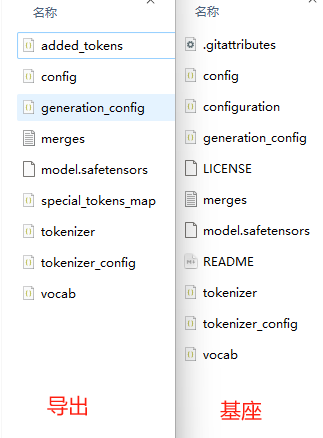
- 可以到Chat中测试导出的新模型,只需改变模型地址即可,无需再选择检查点,也可到达同样的效果
导入Ollama运行
我们的模型不进行模型转换的话,无法在Ollama中使用,因为Ollama不支持我们这种safetensors 格式的模型,需要将其转为GGUF格式,详见ollama。
推荐使用llama.cpp: LLM inference in C/C++转换为GGUF文件,即可导入Ollama,交给大家自己摸索,他不仅仅可用转换,更大的作用是量化模型,这个具体我也没了解……
双 手 合 十 成 为 自 己 的 神
自 己 所 信 念 的 即 是 信 仰

微 信 号 : L I J J J W E I
Q Q 号 : 2 8 4 8 5 2 7 4 8 5




